library(tidyverse) # for data wrangling
library(alr4) # for the data sets #
library(GGally)
library(ggpmisc)
library(parameters)
library(performance)
library(see)
library(car)
library(broom)
library(modelsummary)
library(texreg)
ggplot2::theme_set(ggplot2::theme_bw())
knitr::opts_chunk$set(
fig.width = 12,
fig.asp = 0.618,
fig.retina = 3,
dpi = 300,
out.width = "100%",
message = FALSE,
echo = TRUE,
cache = TRUE
)
my_gof <- function(fit_obj, digits = 4) {
sum_fit <- summary(fit_obj)
stars <-
pf(sum_fit$fstatistic[1],
sum_fit$fstatistic[2],
sum_fit$fstatistic[3],
lower.tail=FALSE) %>%
symnum(corr = FALSE, na = FALSE,
cutpoints = c(0, .001,.01,.05, 1),
symbols = c("***","**","*"," ")) %>%
as.character()
list(
# `R^2` = sum_fit$r.squared %>% round(digits),
# `Adj. R^2` = sum_fit$adj.r.squared %>% round(digits),
# `Num. obs.` = sum_fit$residuals %>% length(),
`Num. df` = sum_fit$df[[2]],
`F statistic` =
str_c(sum_fit$fstatistic[1] %>% round(digits), " ", stars)
)
}
screen_many_regs <-
function(fit_obj_list, ..., digits = 4, single.row = TRUE) {
if (class(fit_obj_list) == "lm")
fit_obj_list <- list(fit_obj_list)
if (length(rlang::dots_list(...)) > 0)
fit_obj_list <- fit_obj_list %>% append(rlang::dots_list(...))
# browser()
fit_obj_list %>%
screenreg(
custom.note =
map2_chr(., seq_along(.), ~ {
str_c("Model ", .y, " ", as.character(.x$call)[[2]])
}) %>%
c("*** p < 0.001; ** p < 0.01; * p < 0.05", .) %>%
str_c(collapse = "\n") ,
digits = digits,
single.row = single.row,
custom.gof.rows =
map(., ~my_gof(.x, digits)) %>%
transpose() %>%
map(unlist),
reorder.gof = c(3, 4, 5, 1, 2)
)
}Linearity
MP223 - Applied Econometrics Methods for the Social Sciences
Common linear transformations
Power transformation or Box-Cox transformations;
Variables normalization to the standard normal distribution;
Tailor expansion (Cobb-Douglas, Trans-log)
Scatter plots
Code
fig_norm_anscombe <-
norm_anscombe %>%
mutate(data_sample = str_c("Data set ", data_sample))
fig_norm_anscombe %>%
ggplot() +
aes(x, y, group = data_sample) +
geom_point() +
geom_smooth(
data = filter(fig_norm_anscombe, data_sample == "Model 2"),
method = "lm",
formula = y ~ x + I(x ^ 2)
) +
geom_smooth(
data = filter(fig_norm_anscombe,
data_sample == "Model 3", y < 11)
) +
geom_abline(slope = 0.5, intercept = 3, colour = "red") +
theme_bw() + facet_wrap(. ~ data_sample) 
Residuals vs fitted
Example 2: Wage and Education
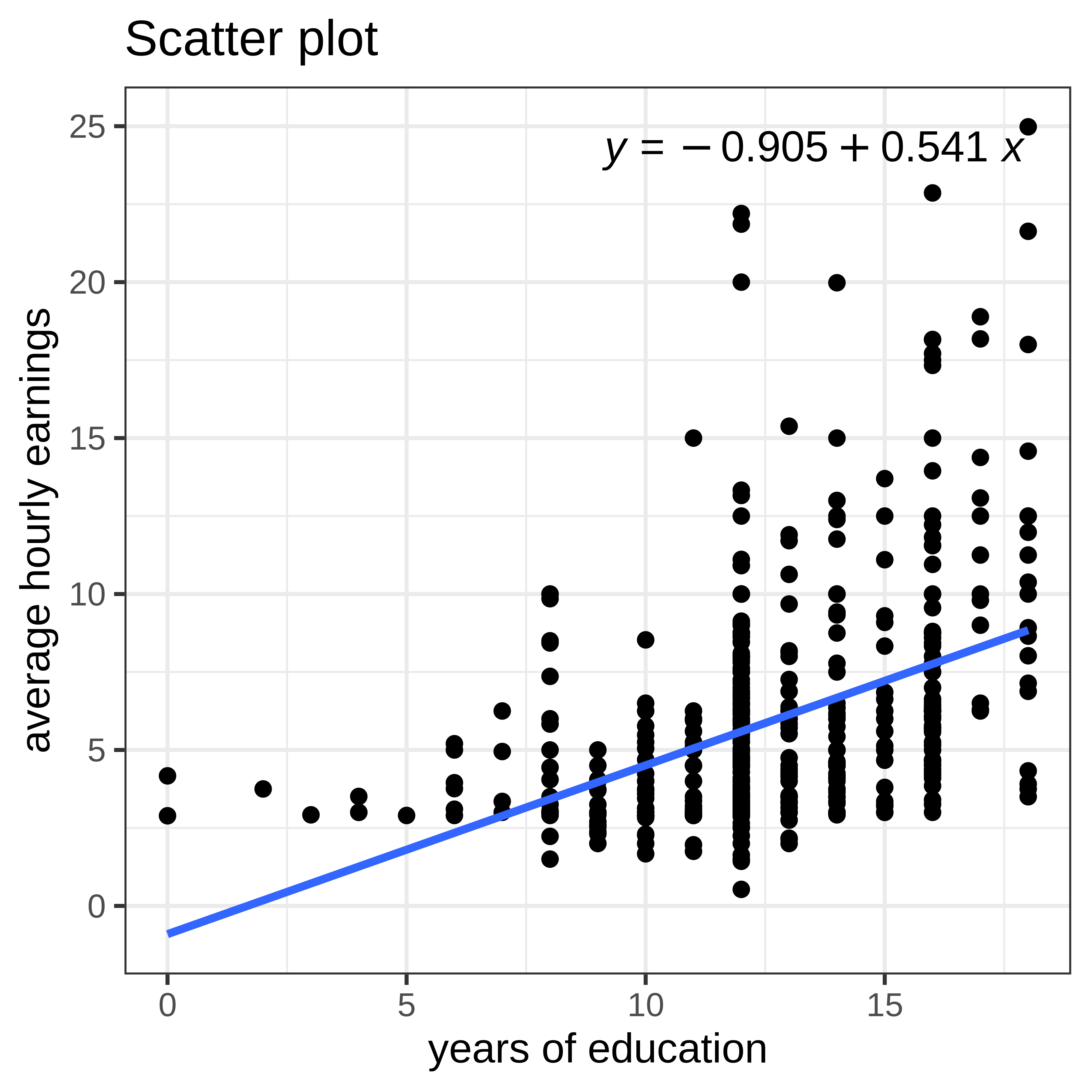
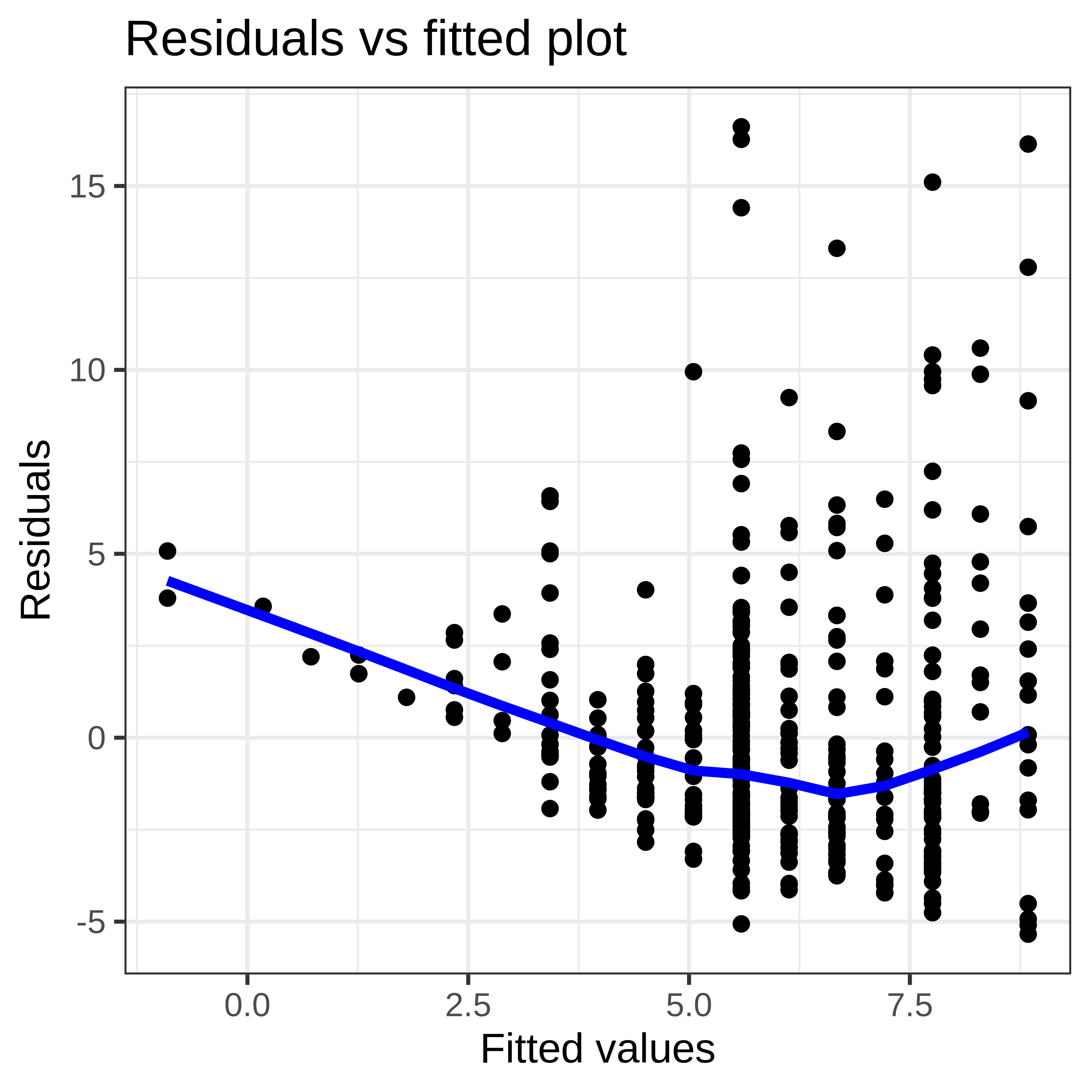
Example 3: Sales and CEO salary
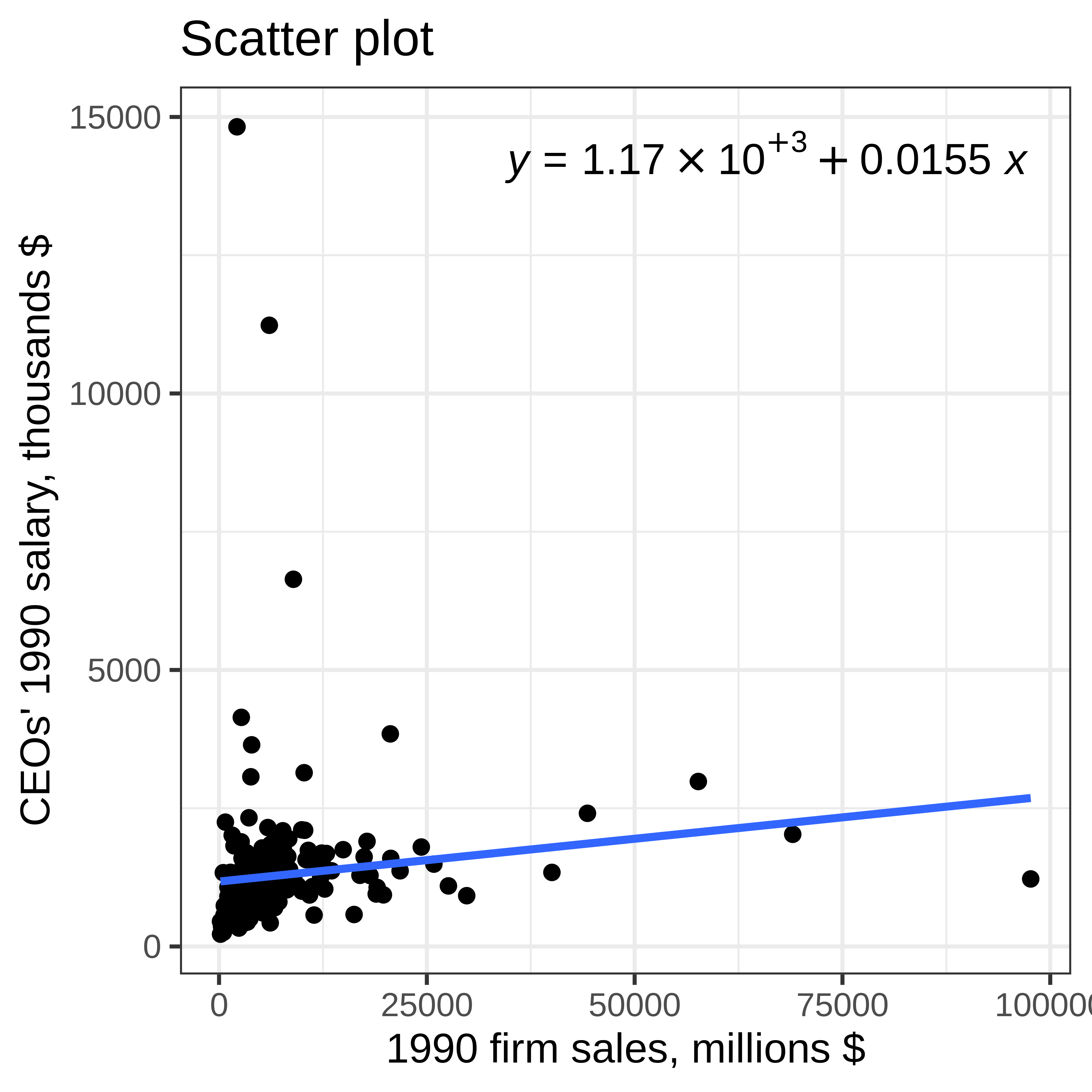
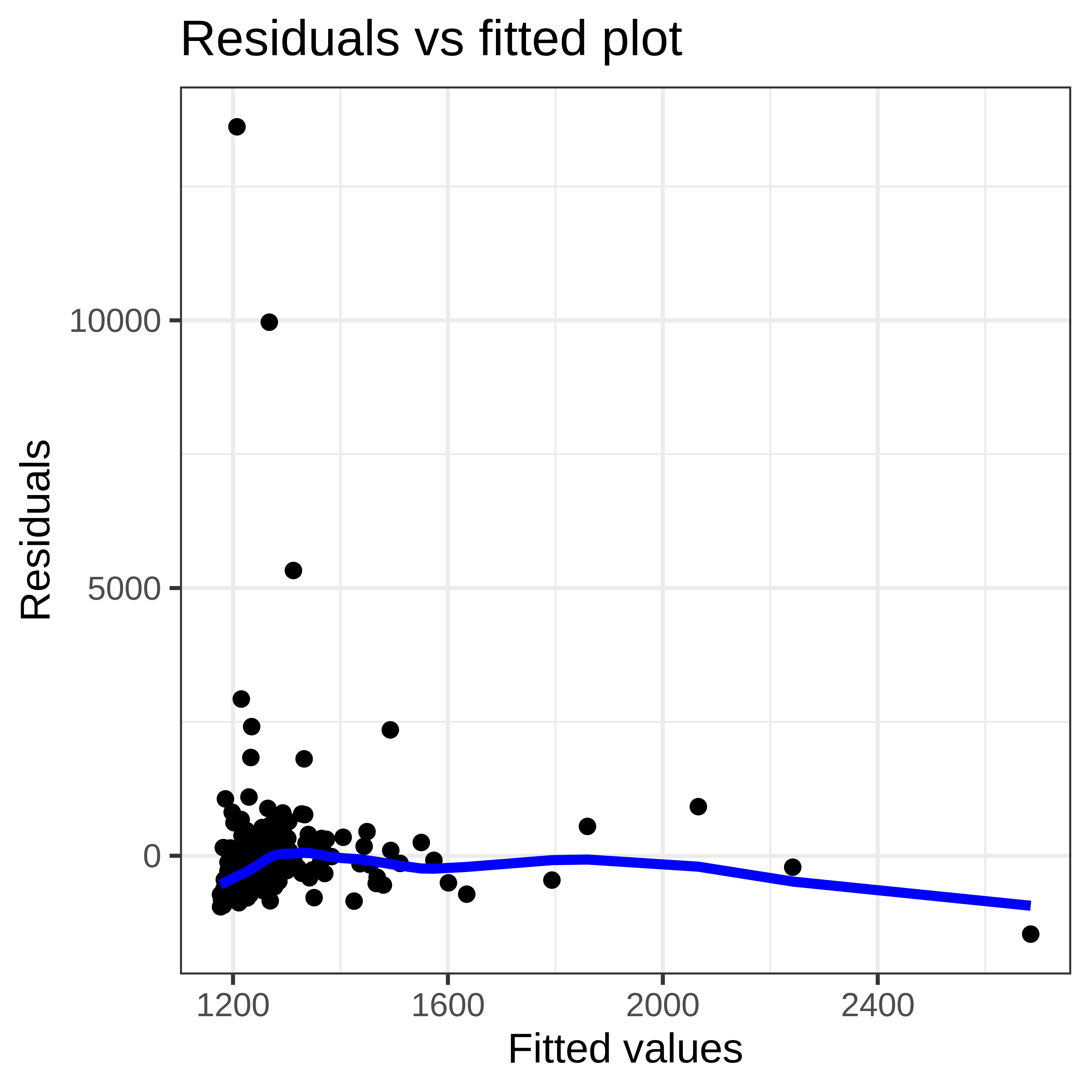
Example 4: Acceptable linearity
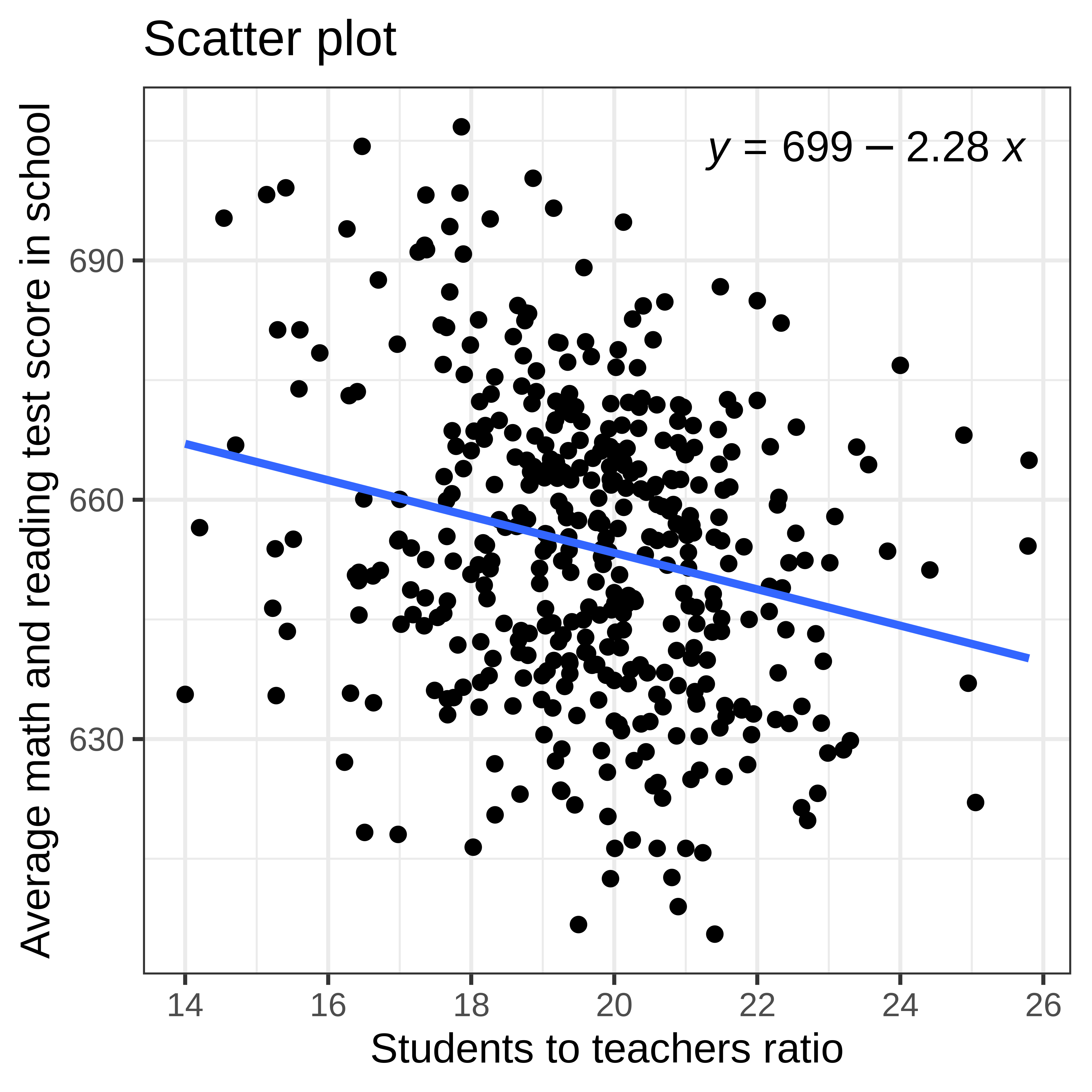
Data visualization
Testing linearity (1/3)
Testing linearity (2/3)
Testing linearity (3/3)
Test stat Pr(>|Test stat|)
Tax -1.1363 0.26183
Dlic -2.4859 0.01670 *
Income 0.0500 0.96036
Miles -0.2036 0.83961
Tukey test -2.3136 0.02069 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Checking linearity (1/2)
Checking linearity (2/2)
Test stat Pr(>|Test stat|)
Tax -1.0767 0.28737
Dlic -1.9219 0.06096 .
Income -0.0840 0.93345
log(Miles) -1.3473 0.18463
Tukey test -1.4460 0.14818
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1