library(tidyverse)
library(alr4)
library(skimr)
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_minimal(base_size = 16))
# set default figure parameters for knitr
knitr::opts_chunk$set(
fig.width = 8,
fig.asp = 0.618,
fig.retina = 3,
dpi = 300,
out.width = "80%"
)Exploring numerical data
MP223 - Applied Econometrics Methods for the Social Sciences
Using dplyr::summarise() (1/3)

Using dplyr::group_by() + dplyr::summarise() (1/3)

skimr package
![]()
Package for Summary statistics
Documentation ropensci/skimr + Source code
Learn by doing Using Skimr
Key functions:
skimr::skim()
report package
![]()
Package for Summary statistics!
Documentation easystats/skimr
Learn by doing Using Skimr
Key functions:
skimr::skim()
Important
This is an experimental package! It does not support some types of the variables and may break or produce an error.
Boxplot: basics
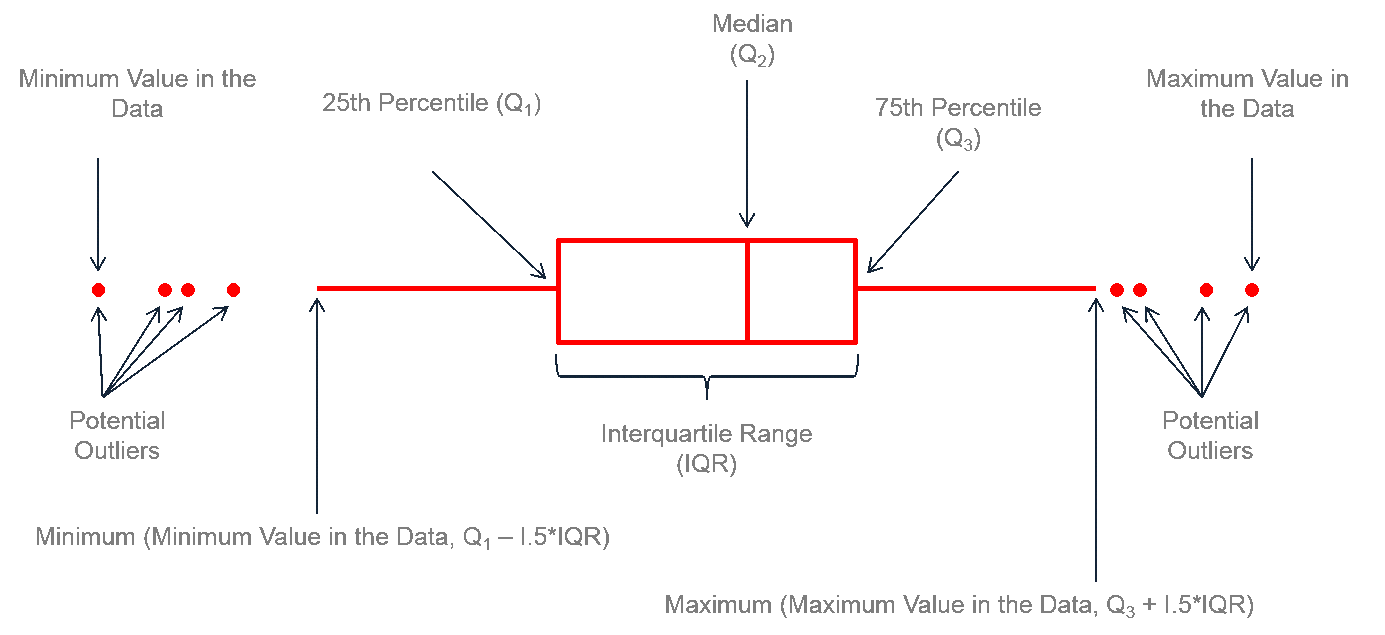
Important
Check out https://www.r-graph-gallery.com/boxplot.html;
Boxplot explanation: https://www.data-to-viz.com/caveat/boxplot.html
Boxplot (1/4)

Boxplot (2/4)

Boxplot (3/4)
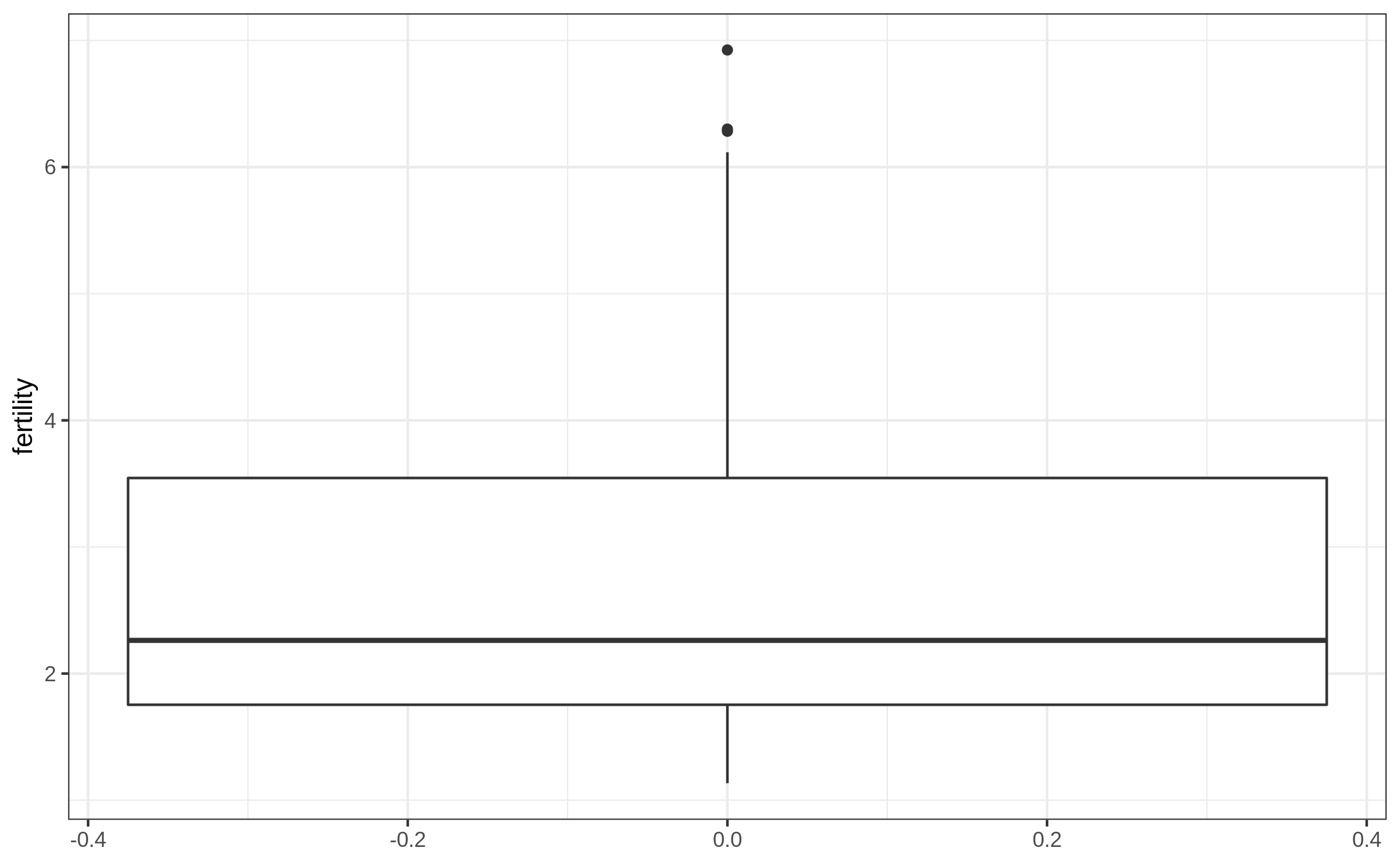
Boxplot (4/4)
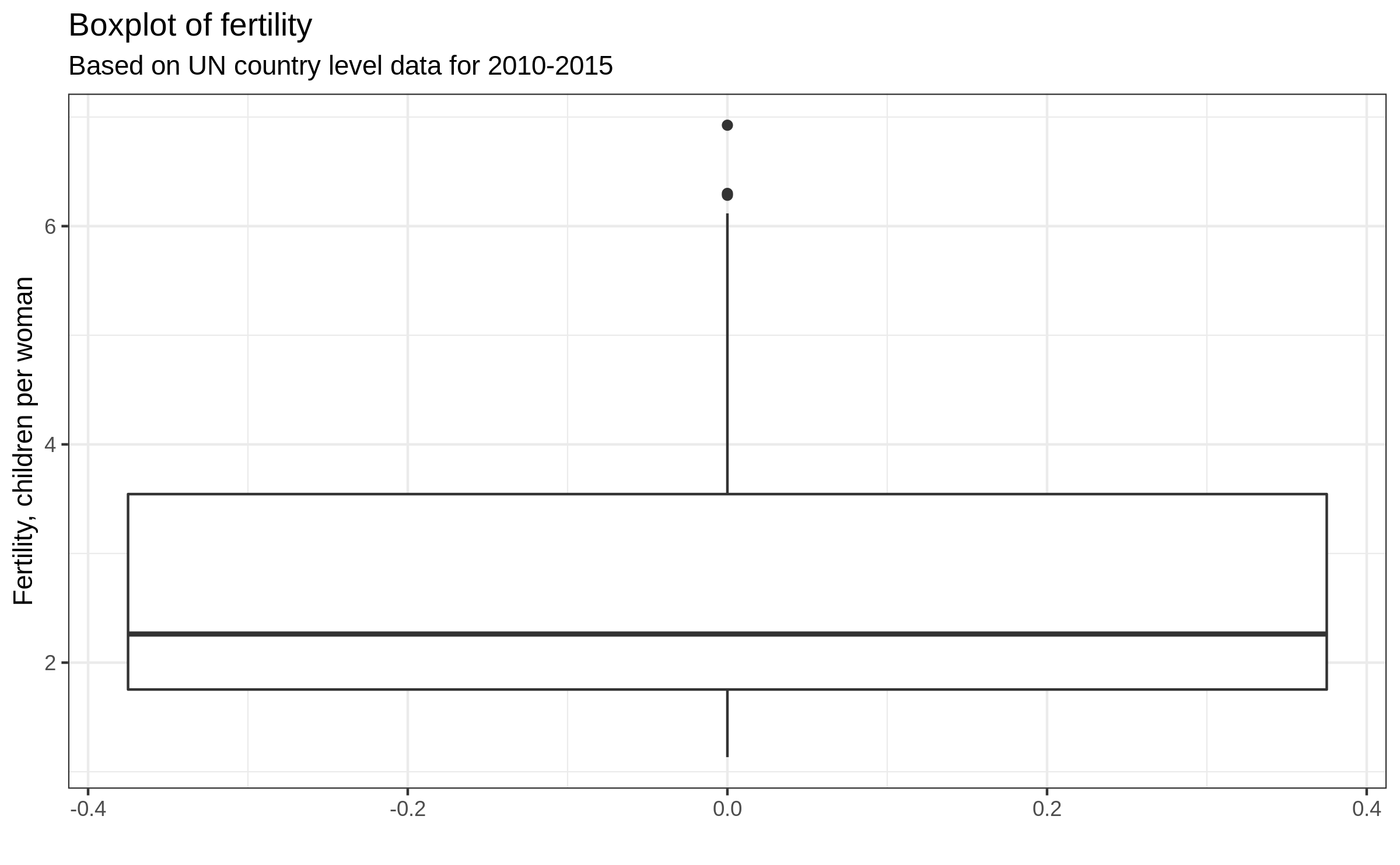
Boxplot (4/4)
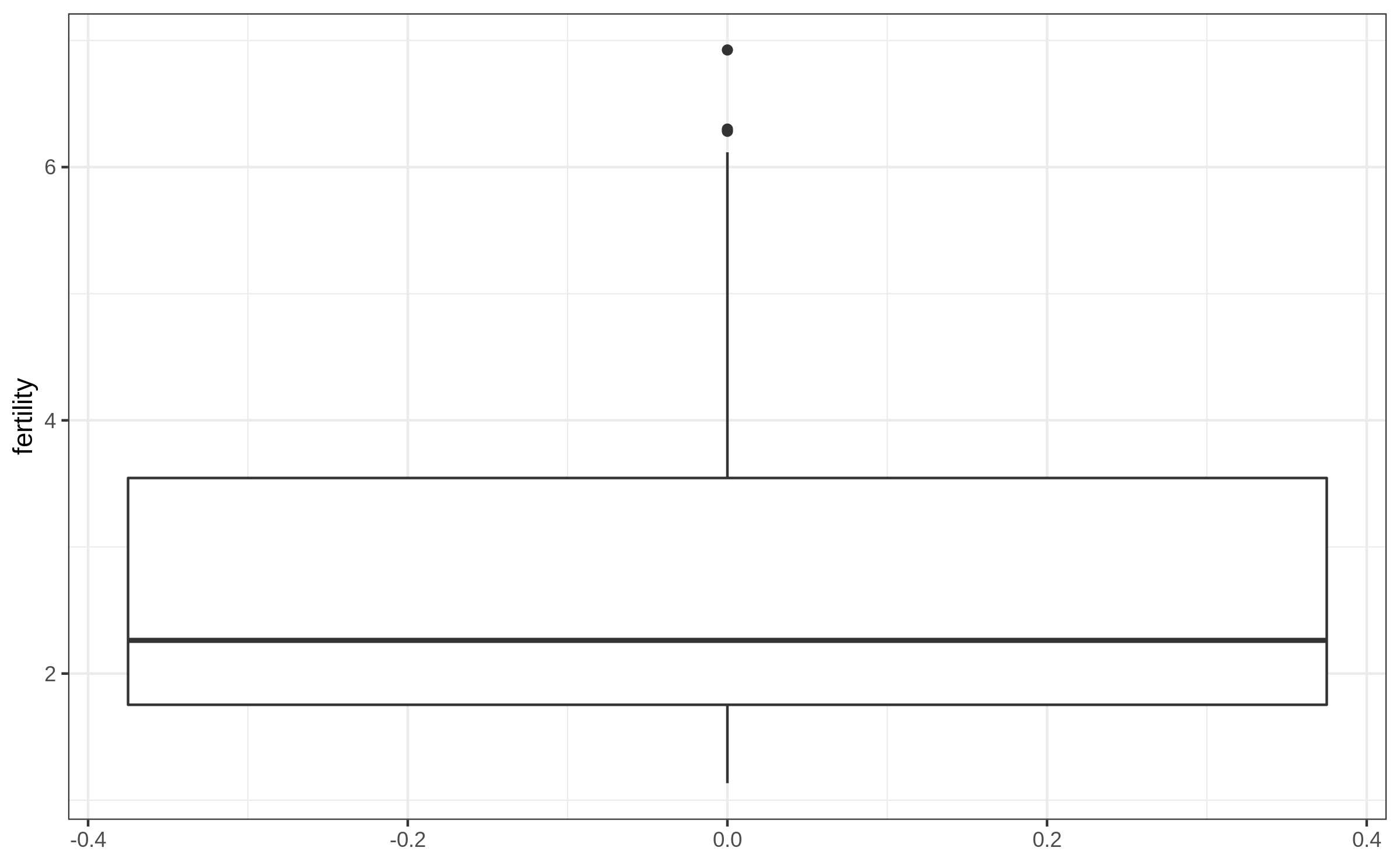
Boxplot by groups (1/3)
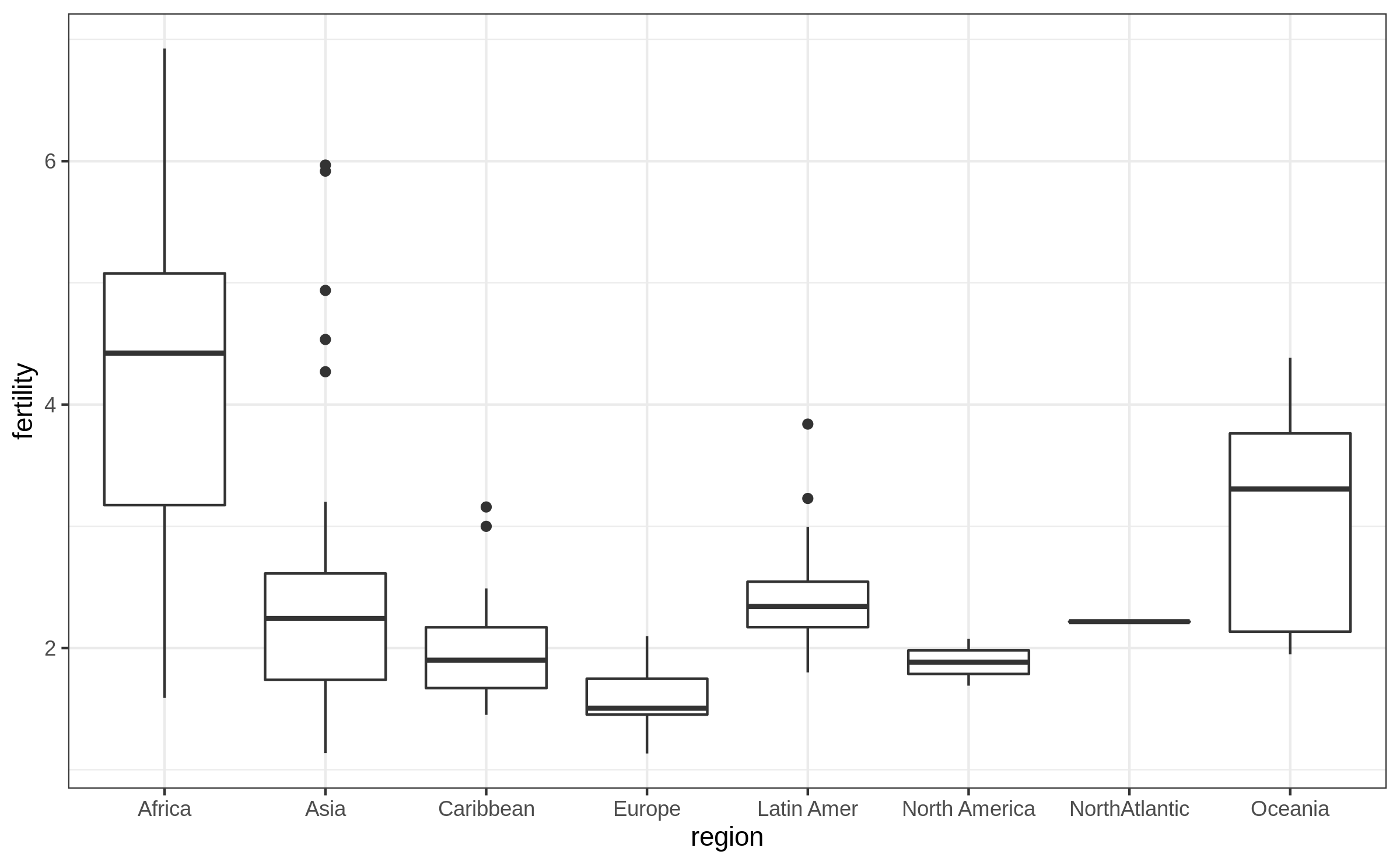
Boxplot by groups (2/3)
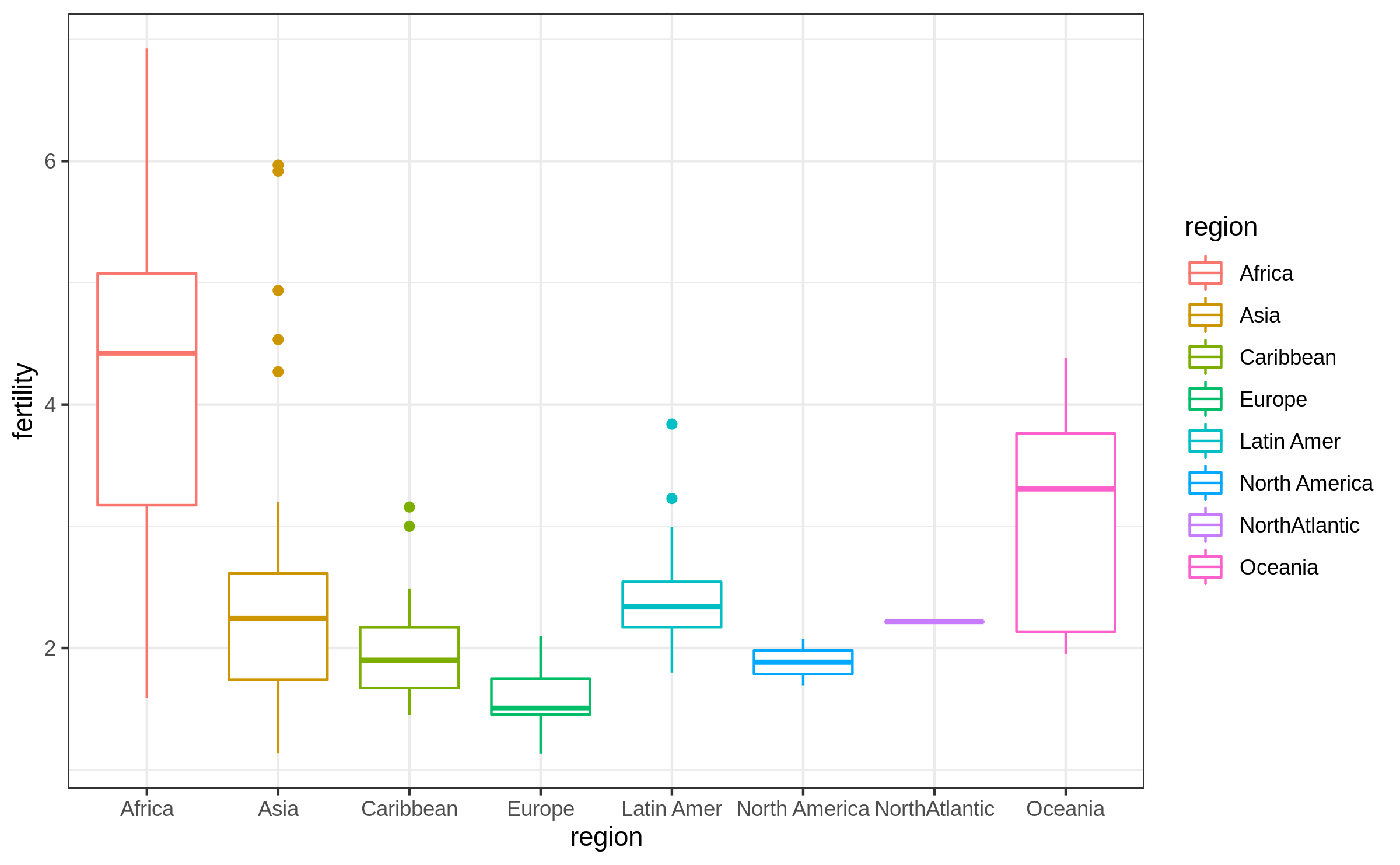
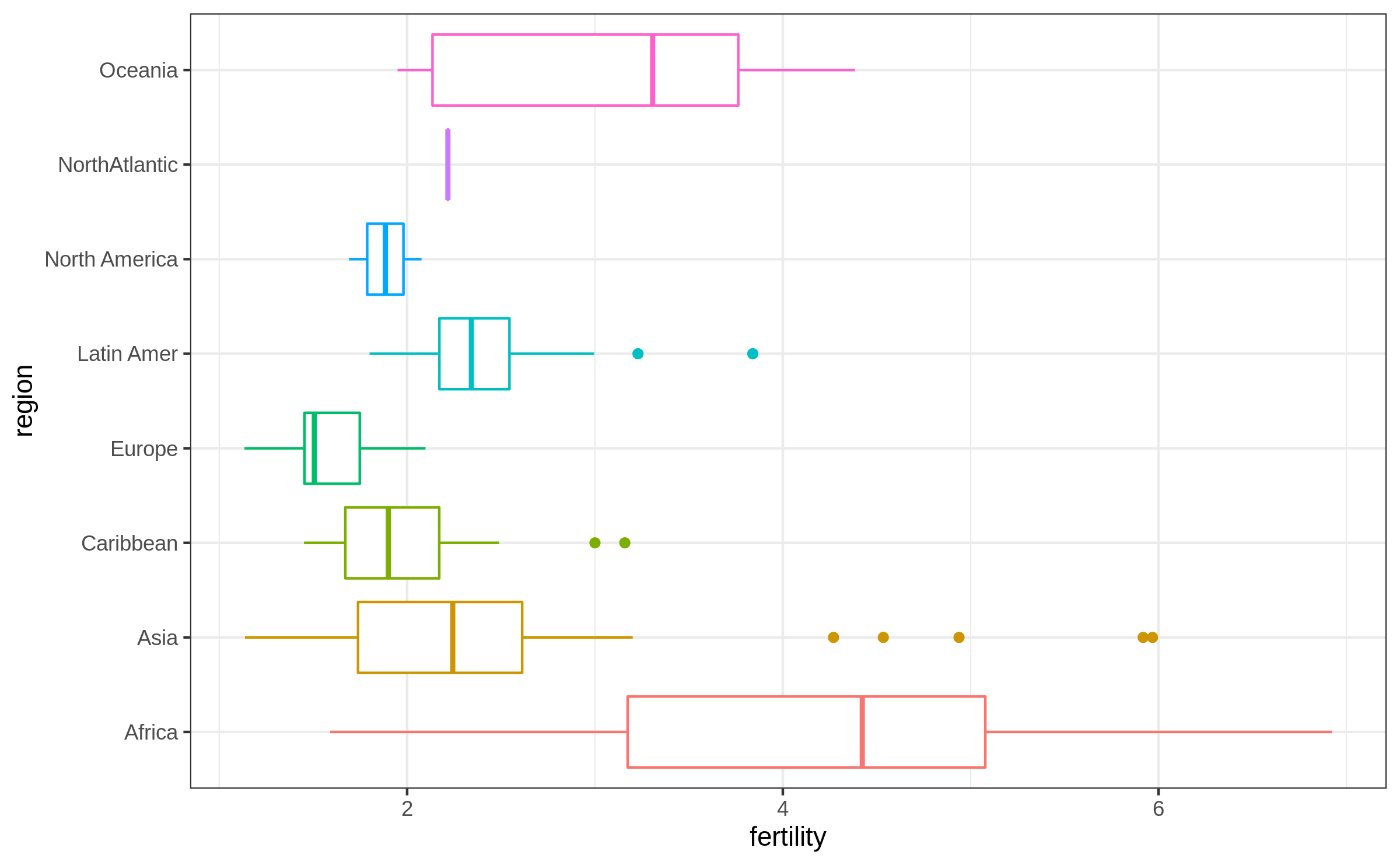
Boxplot by groups (3/3)
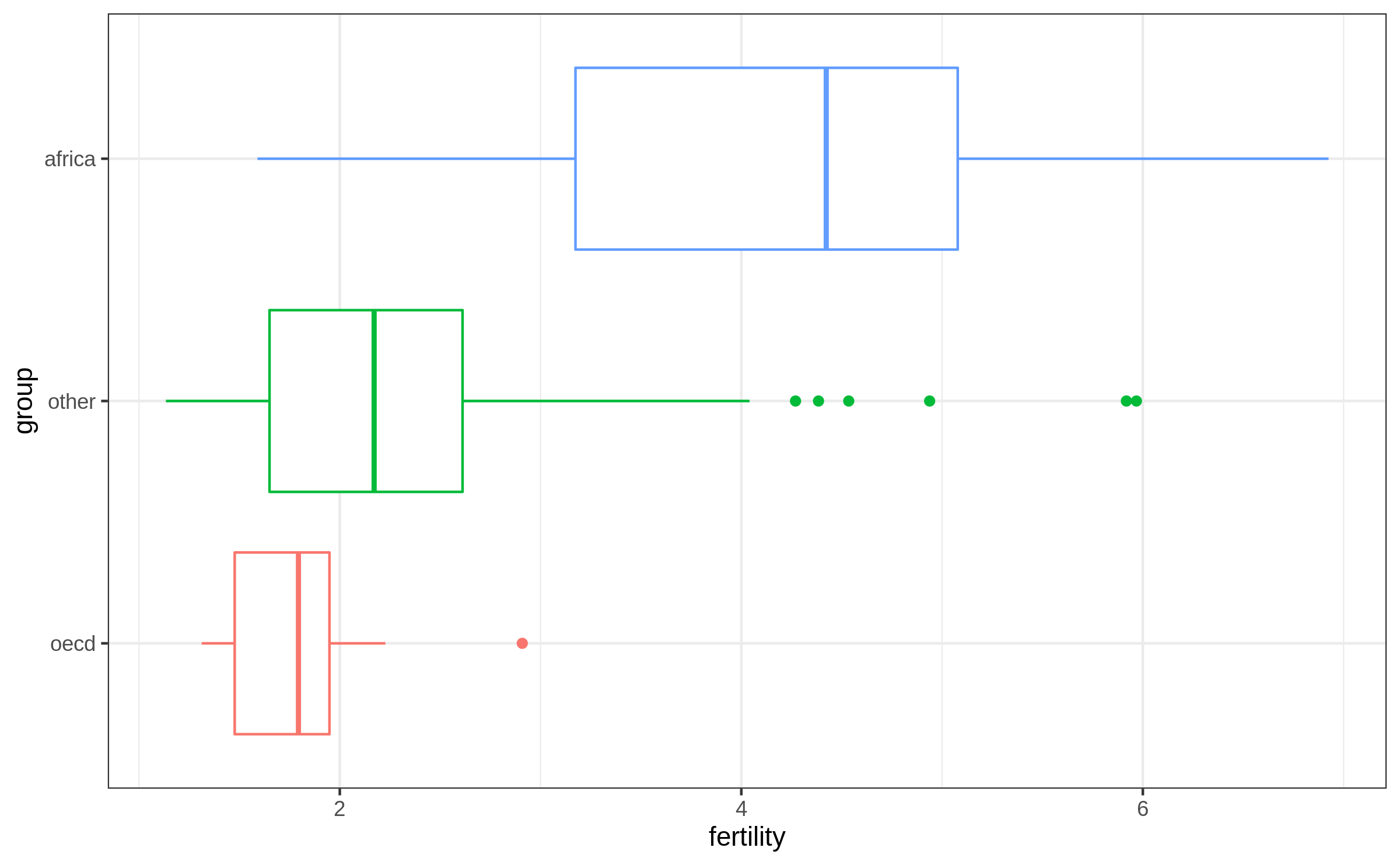
Causal question on boxplot!
Does a country group has a causal effect on fertility?
Histogram: basics
Important
Check the gallery https://r-graph-gallery.com/histogram.html;
Learn about histograms here: THE BOXPLOT AND ITS PITFALLS
Histogramus simplicius

Histogramus simplicius
Histogramus simplicius
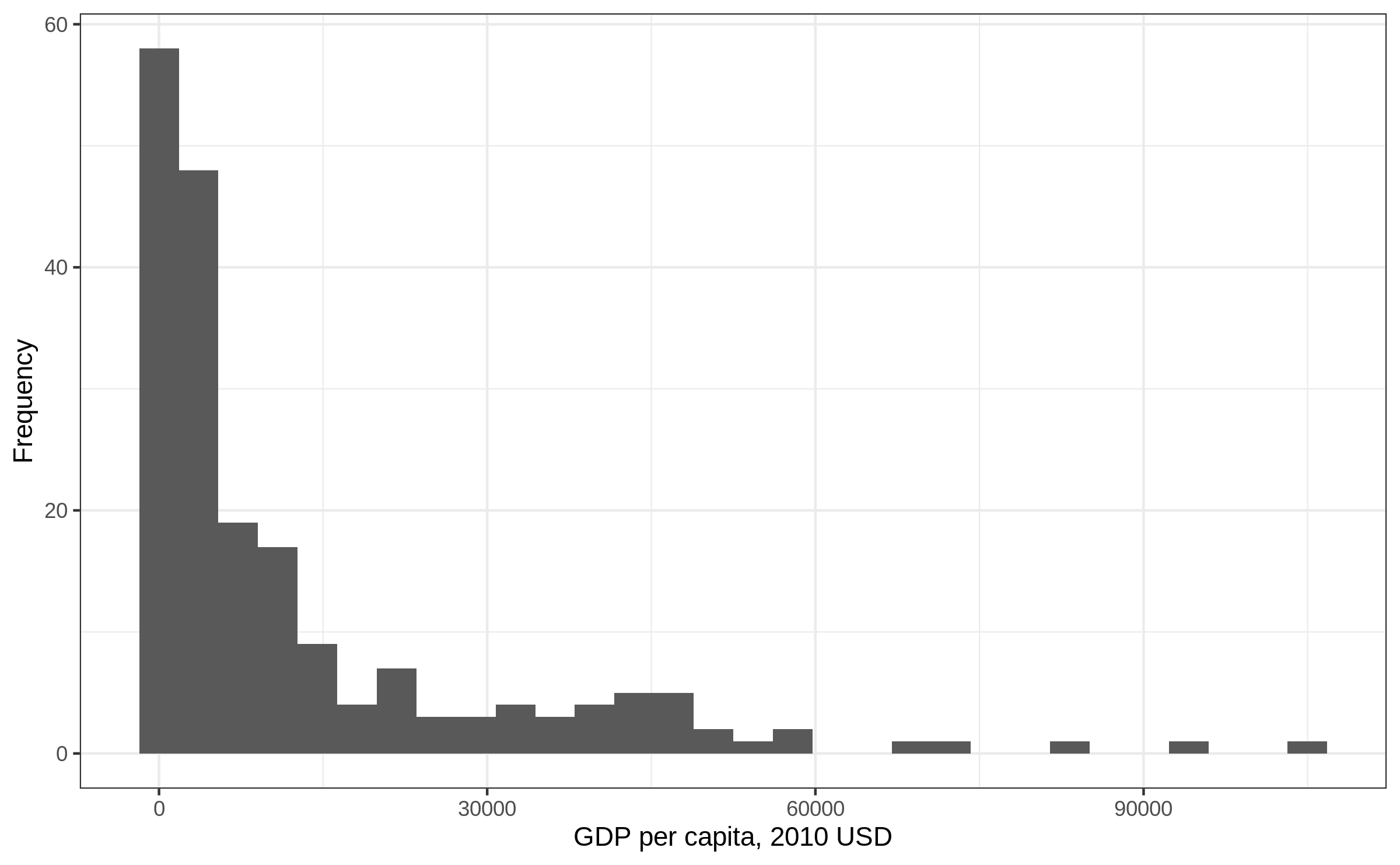
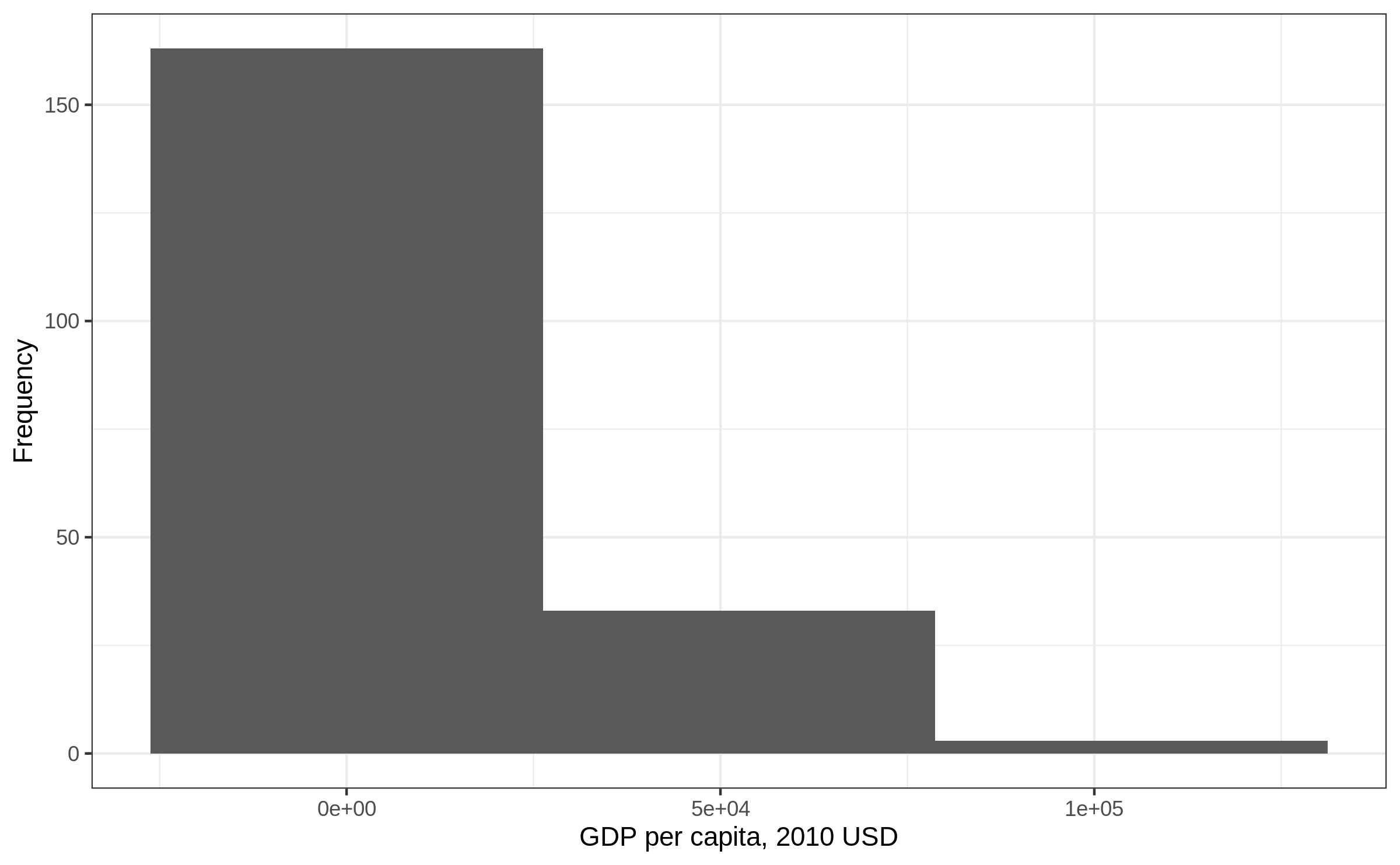
Histogram: bins
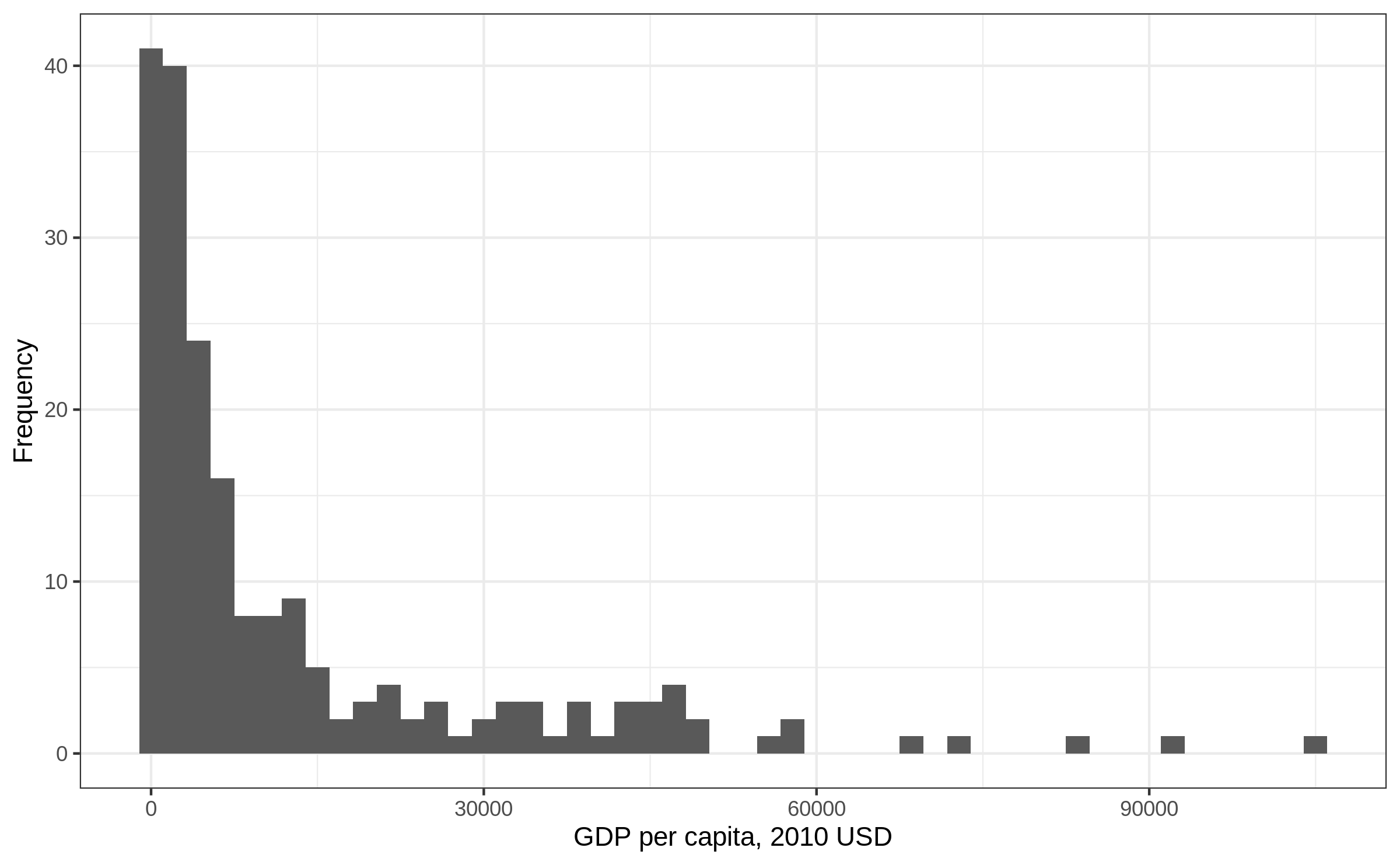
Histogram: bins
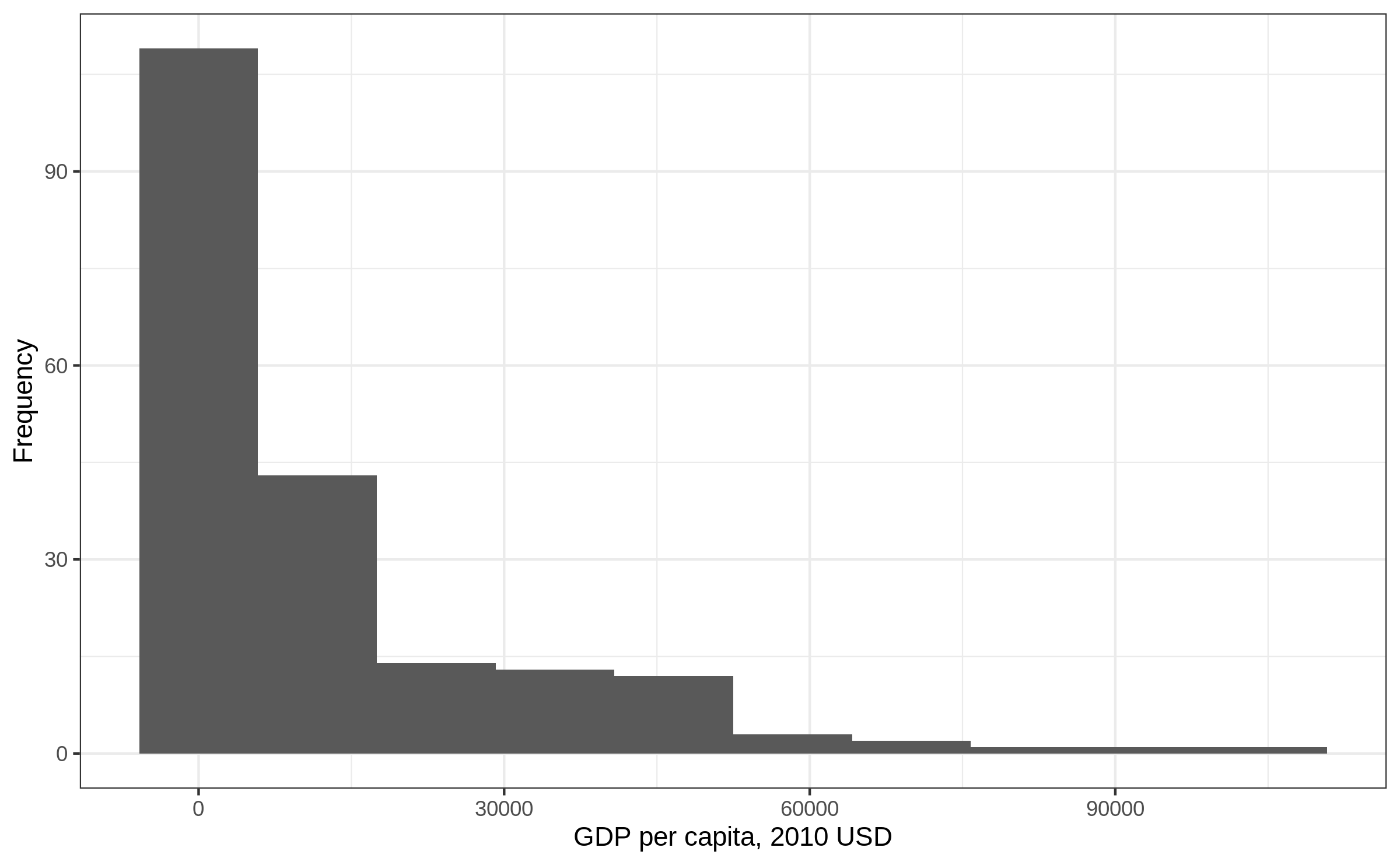
Histogram: bins
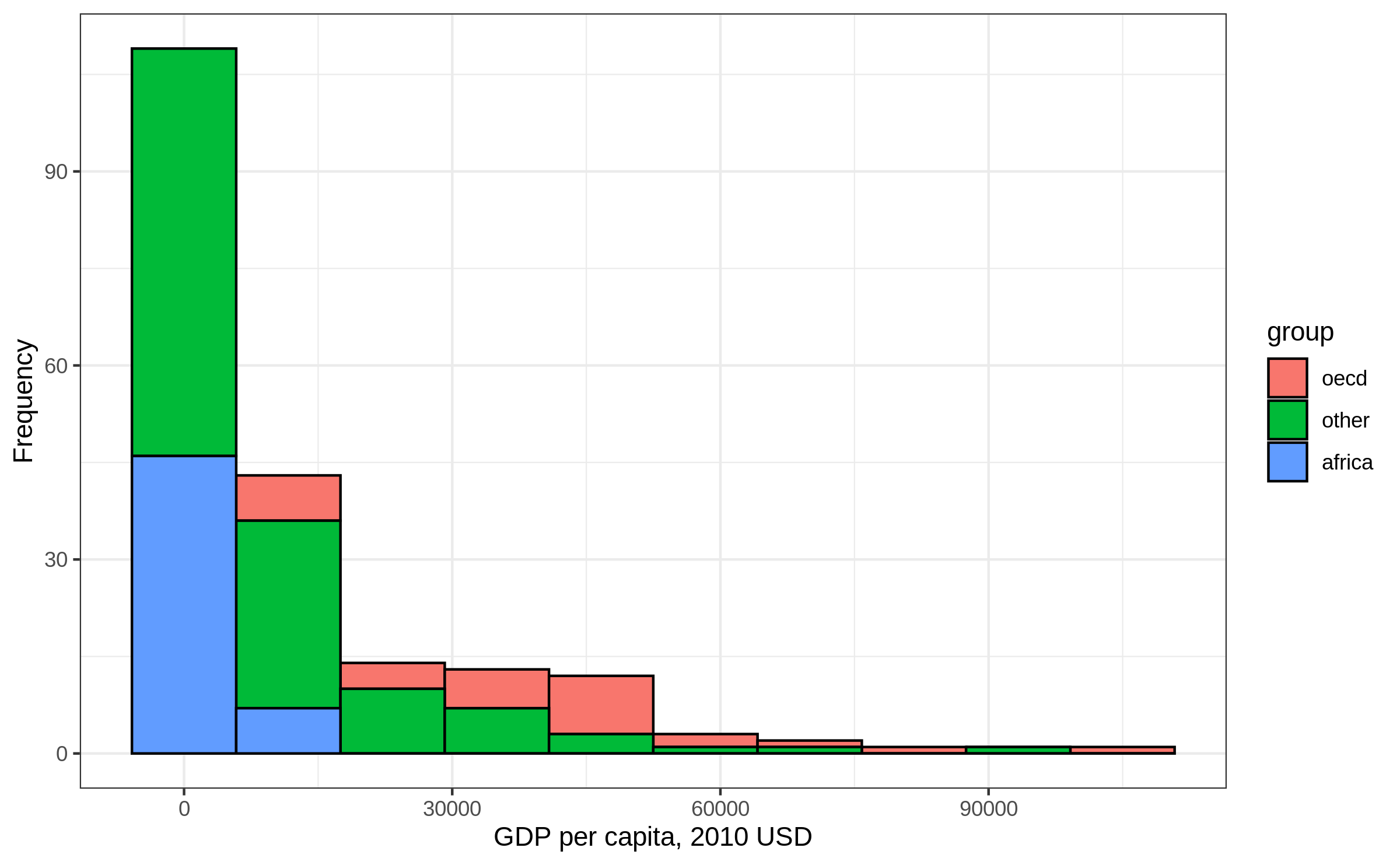
Histogram by group
Histogram by group
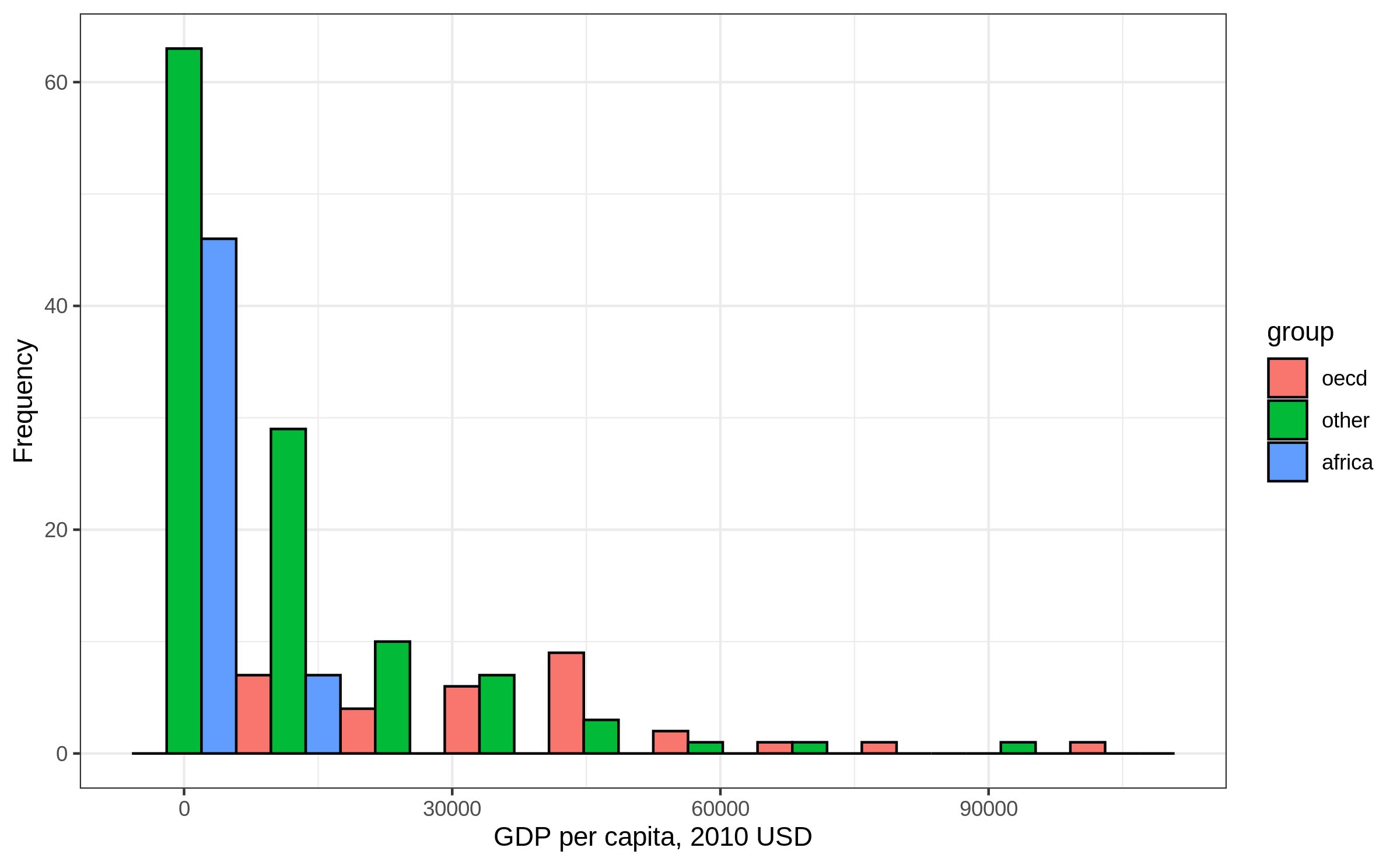
Histogram by group
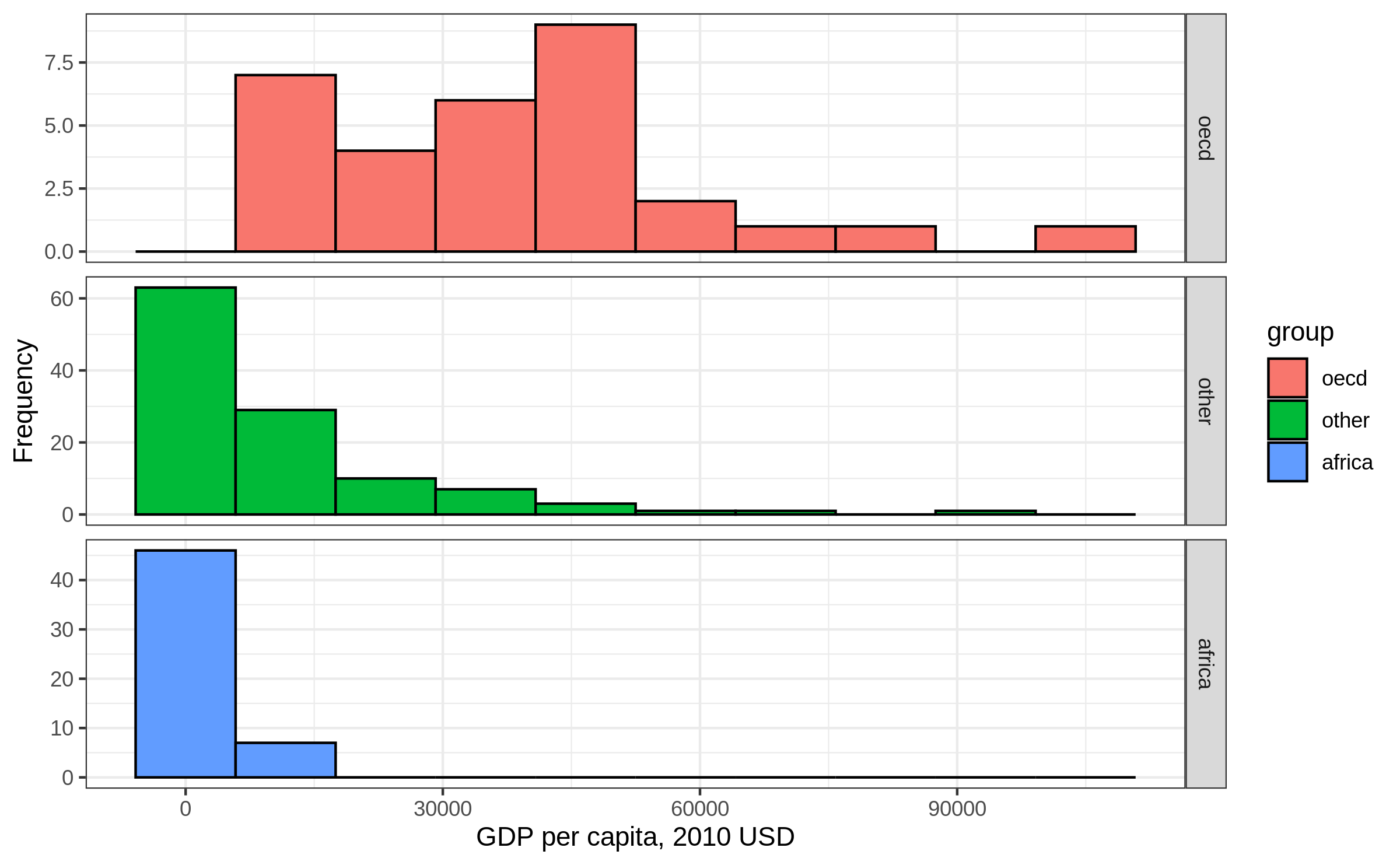
Histogram: x transformation (1)
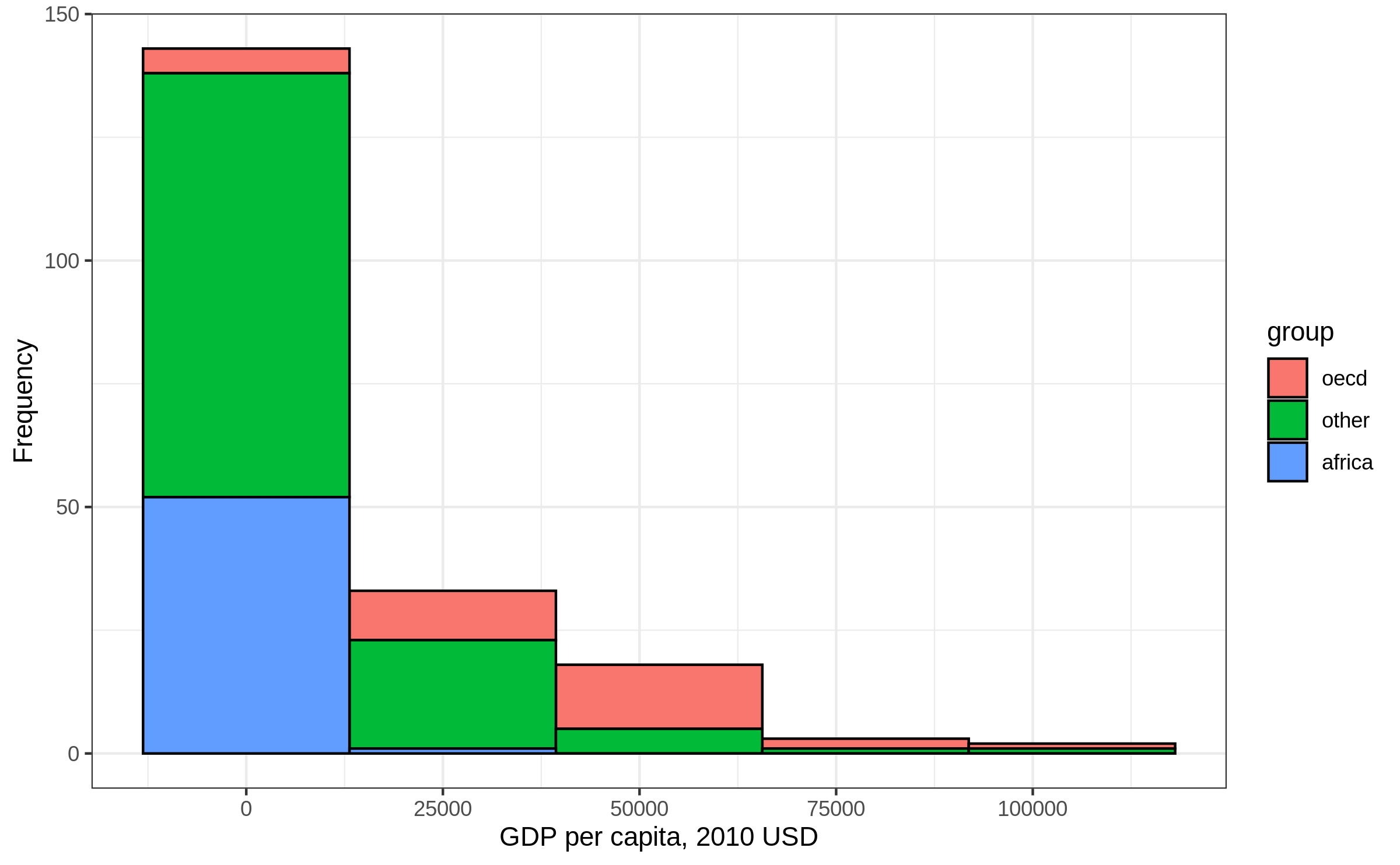
Histogram: x transformation (1)
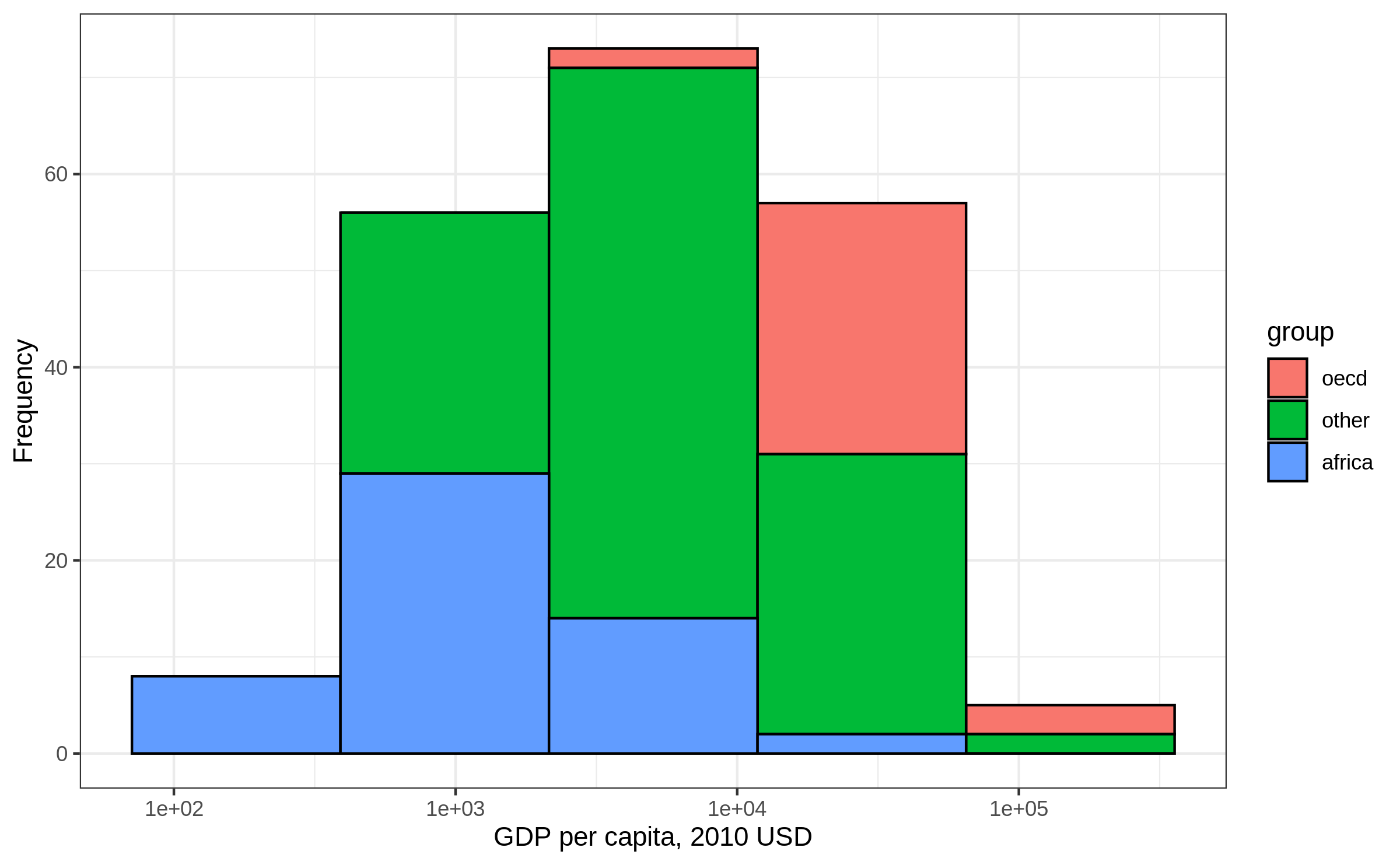
Histogram: x transformation (1)
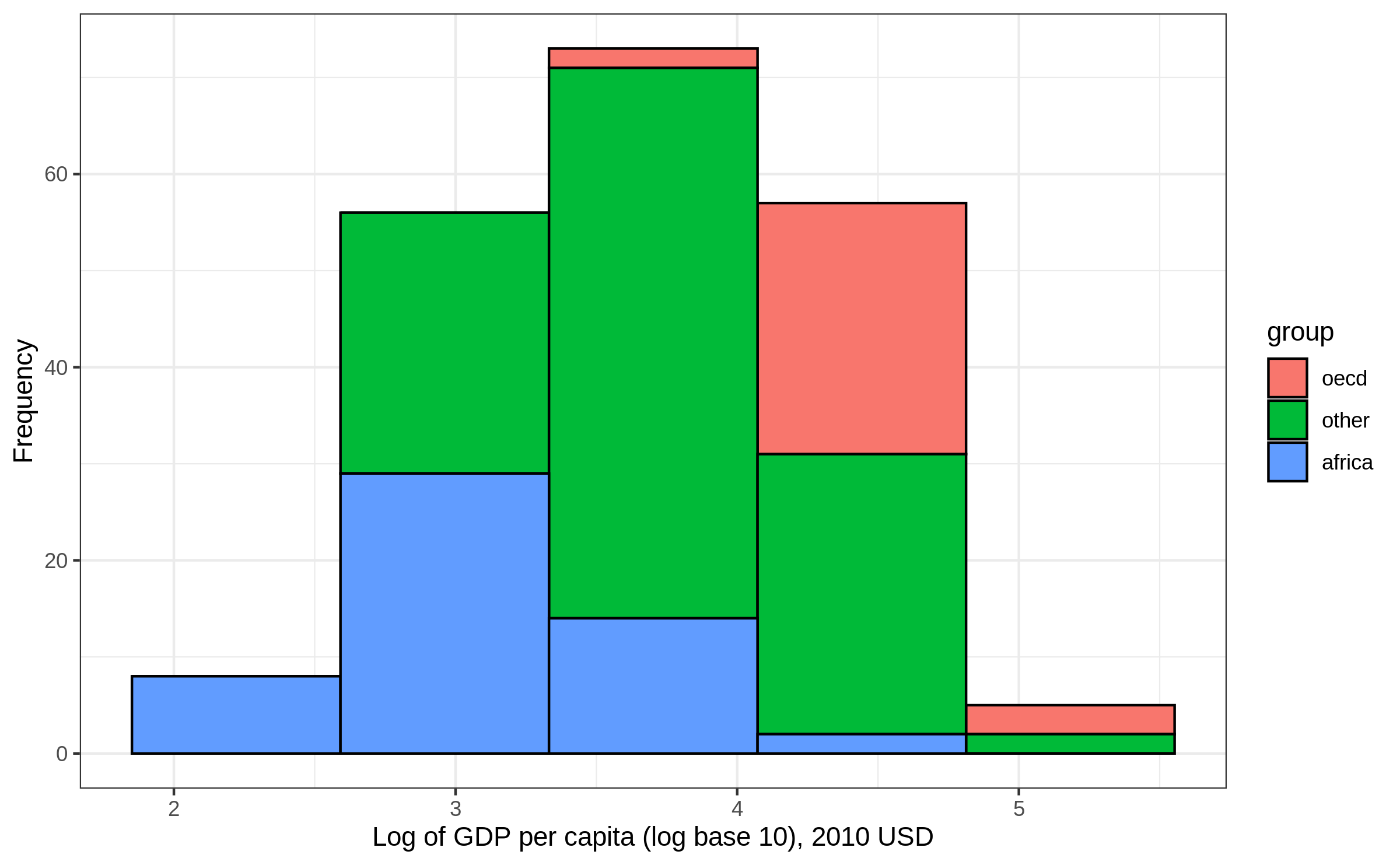
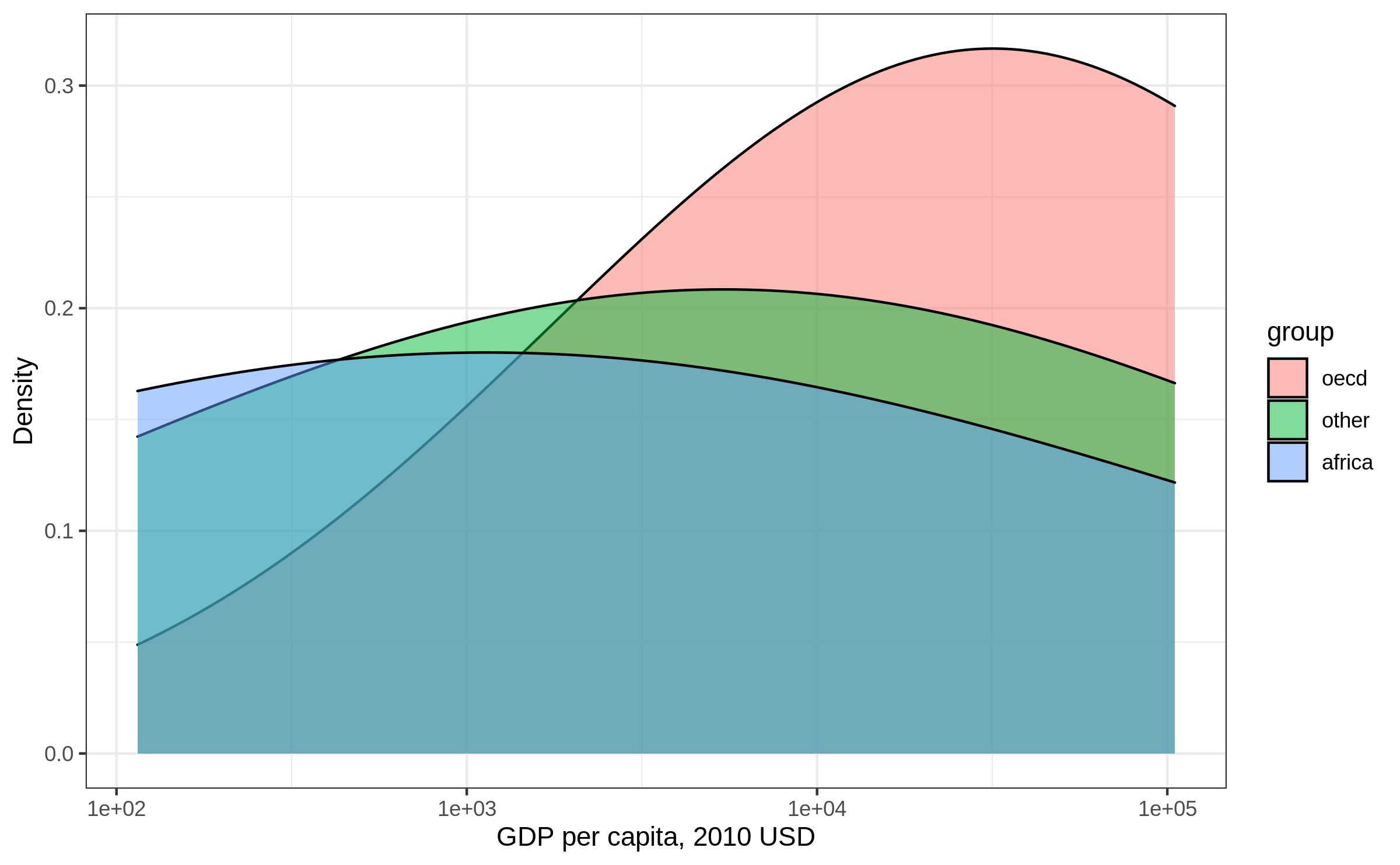
Density plot: example
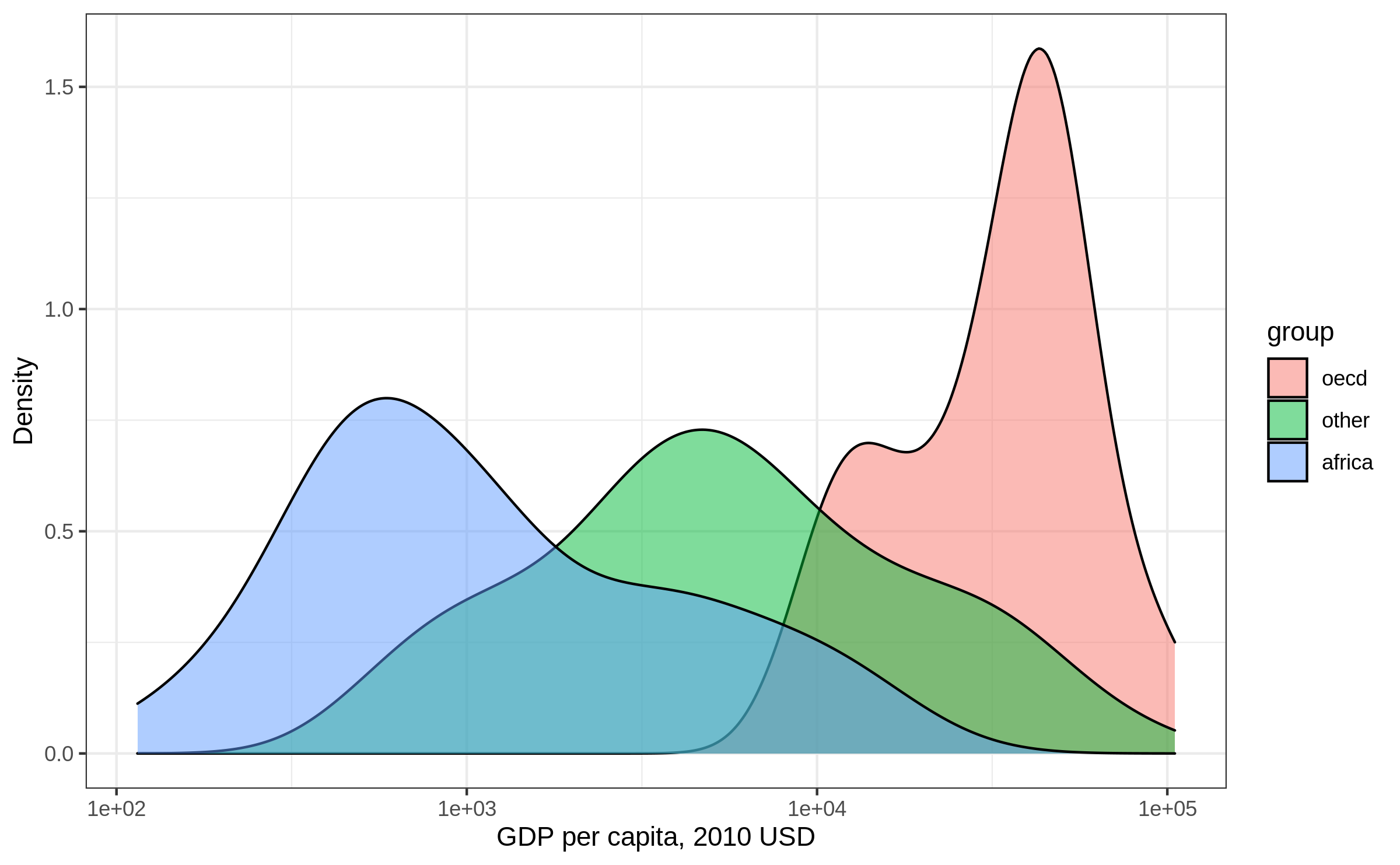
Density plot: adjust
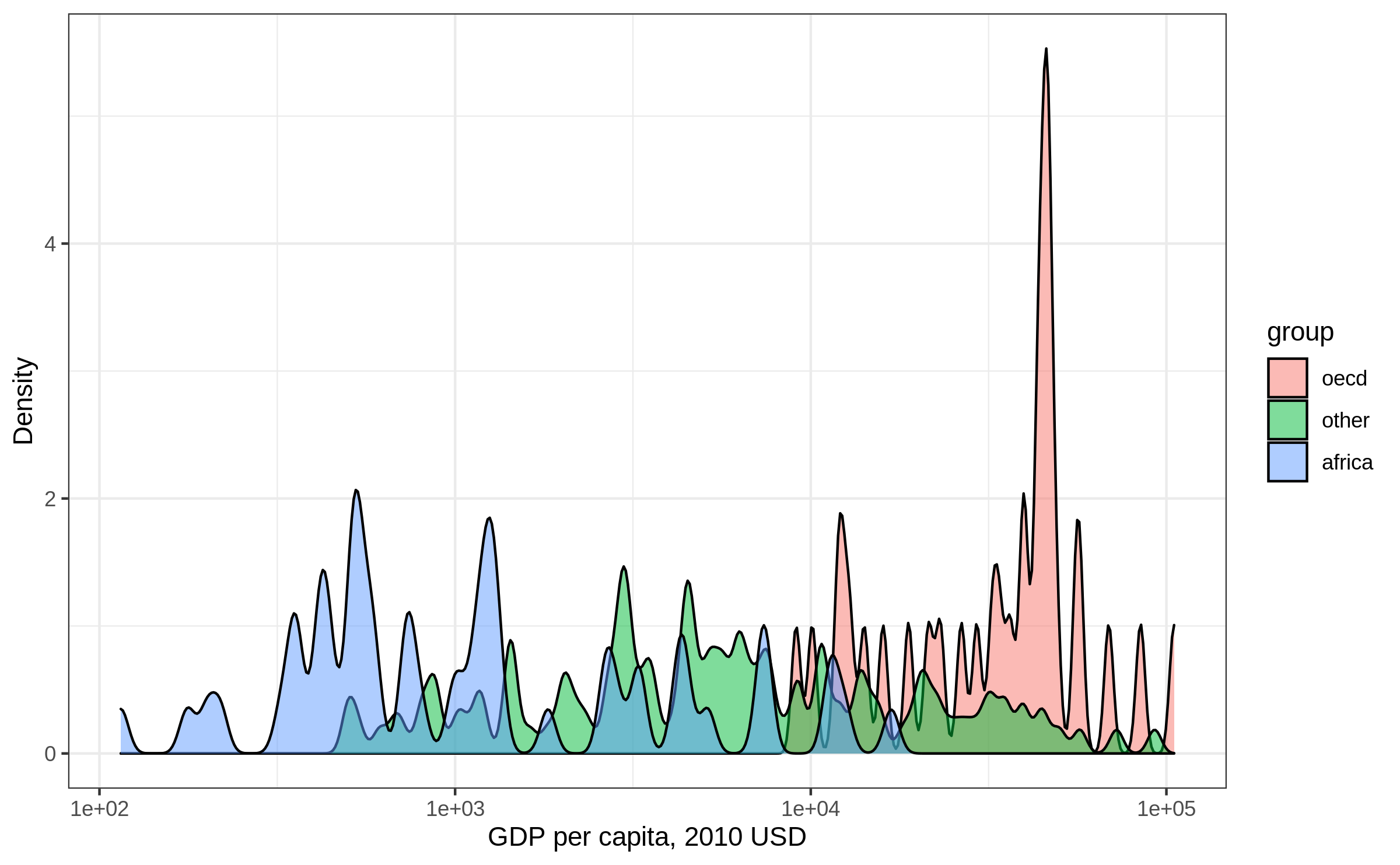
Density plot: adjust
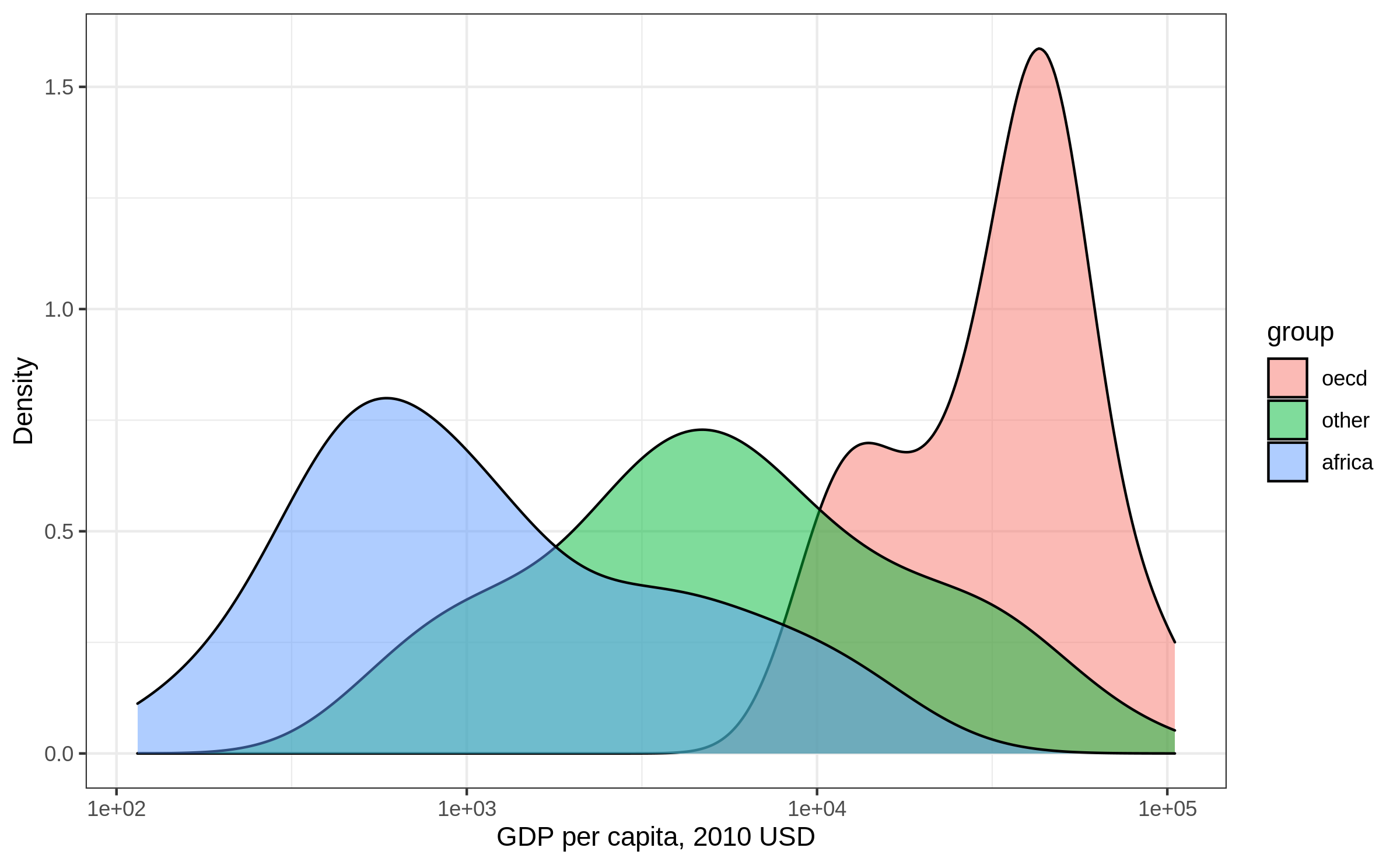
Density plot: adjust
Simple scatter plot

Simple scatter plot
Simple scatter plot
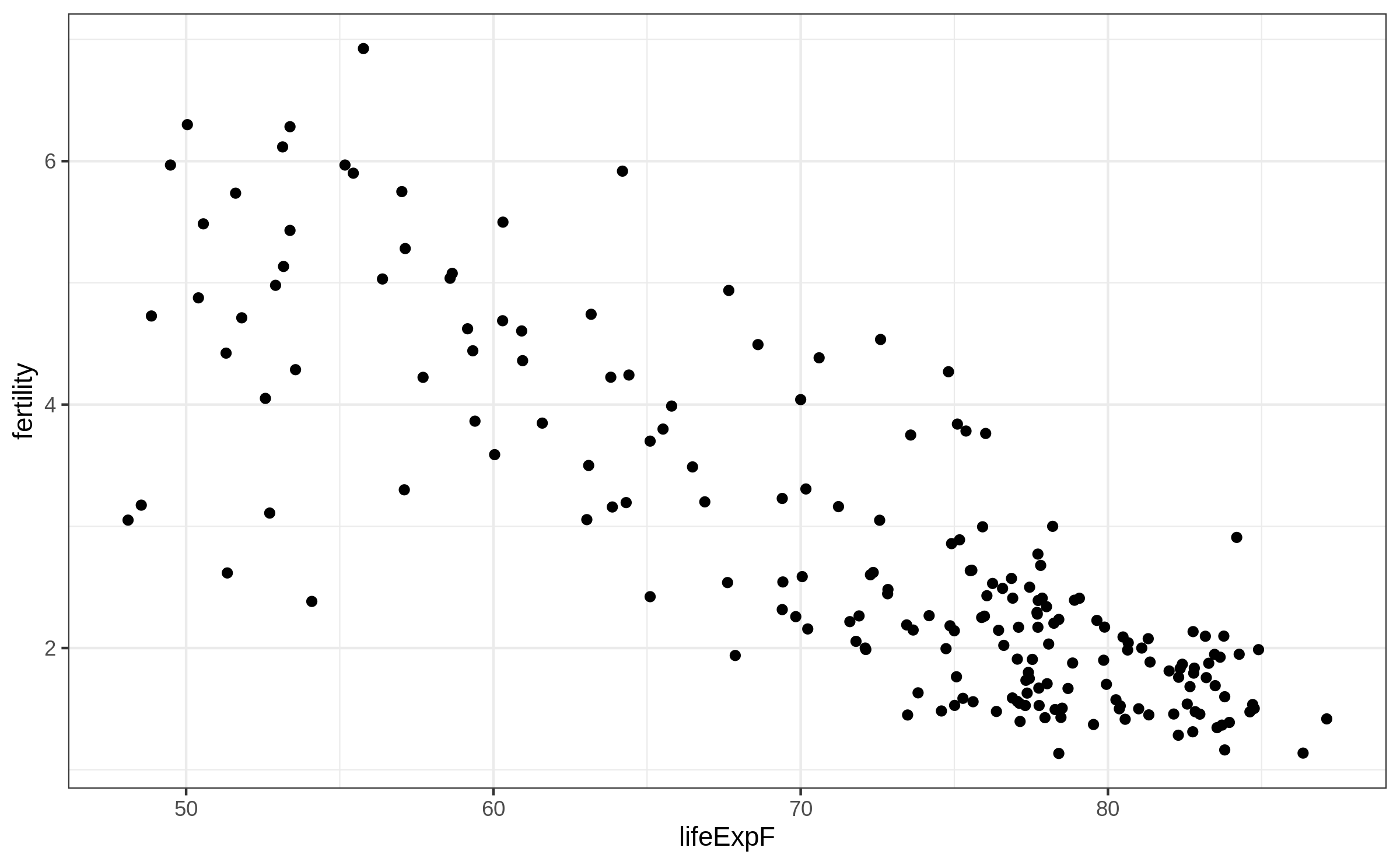
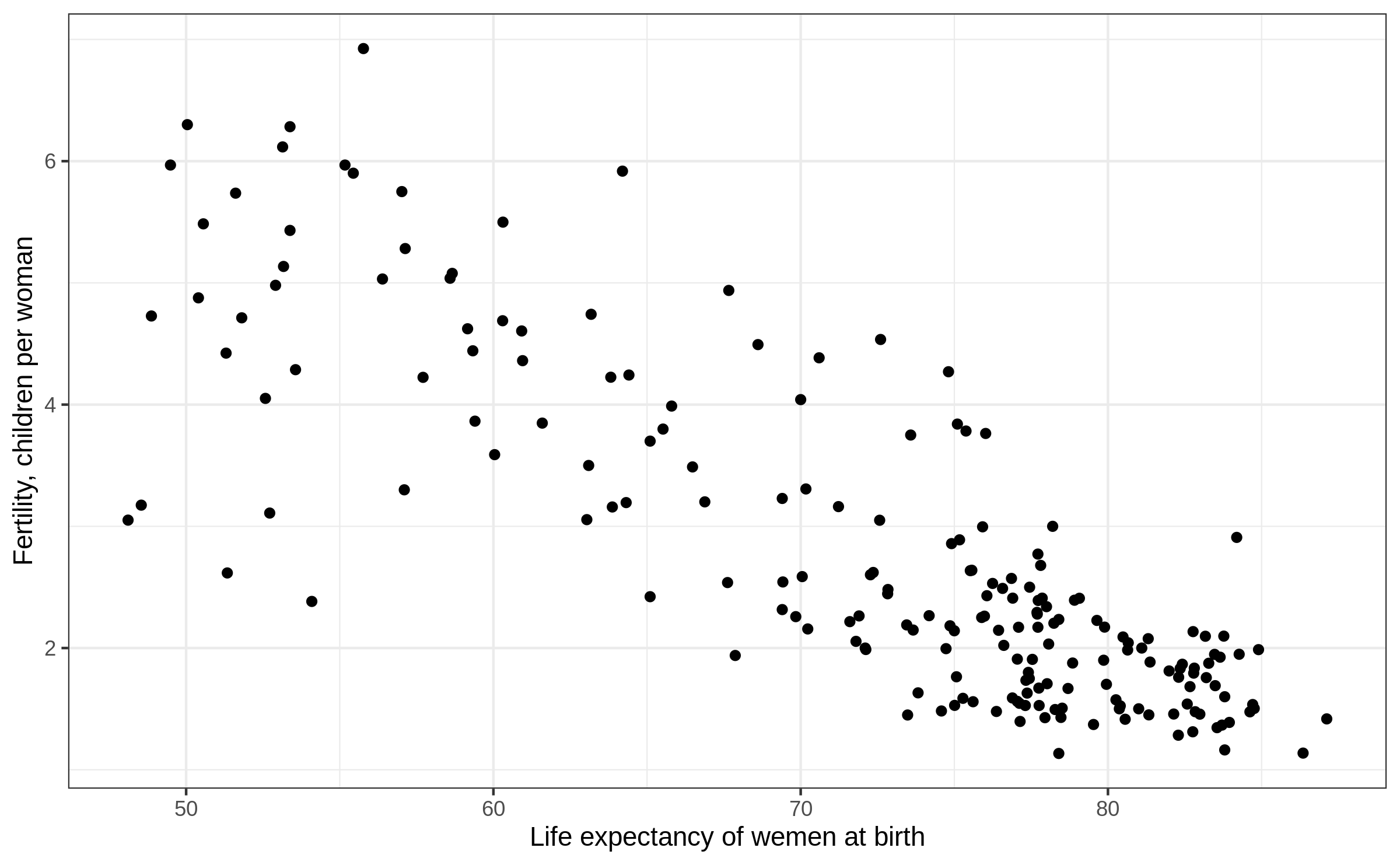
Simple scatter plot
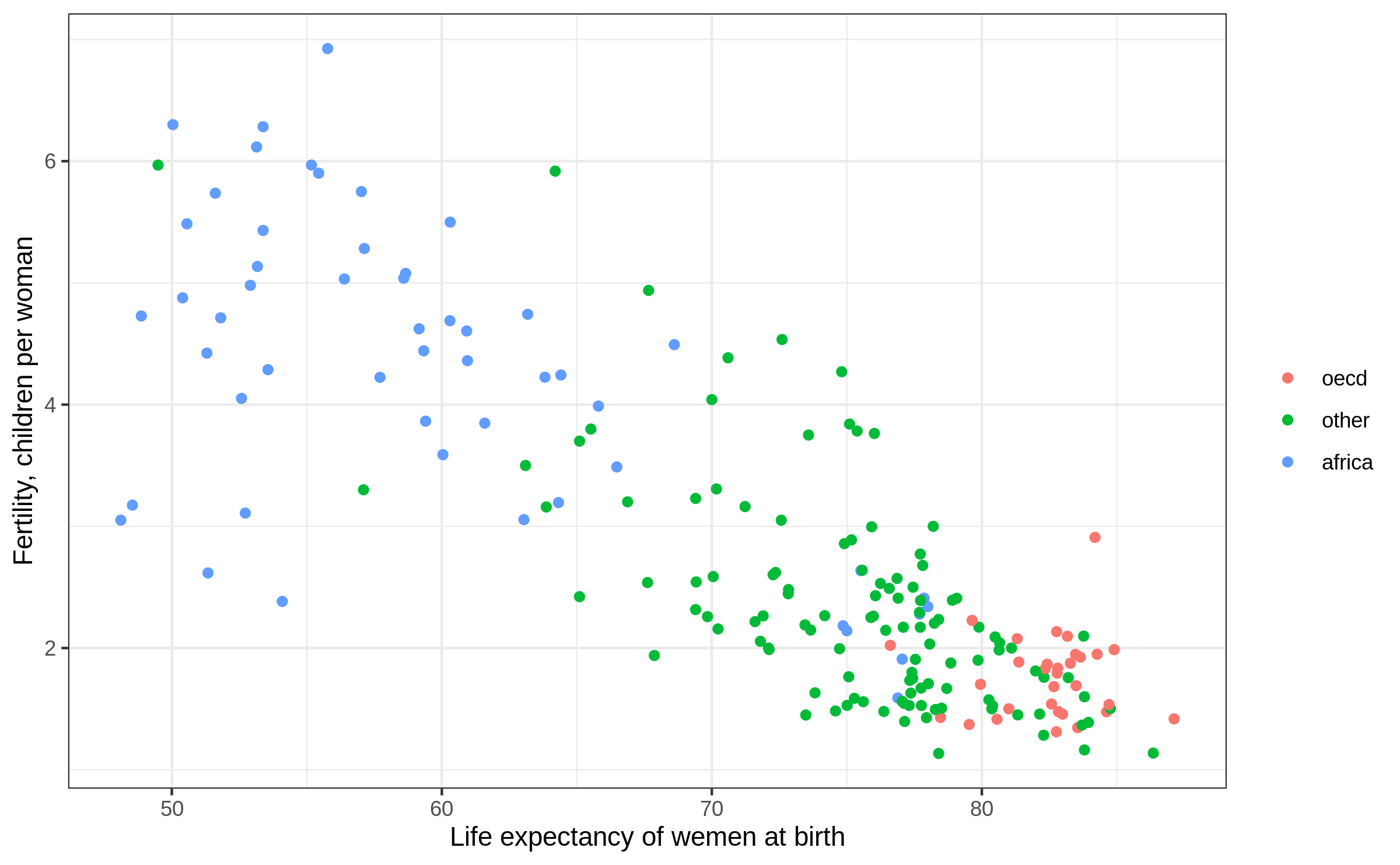
Scatter plot: make it rich with colour
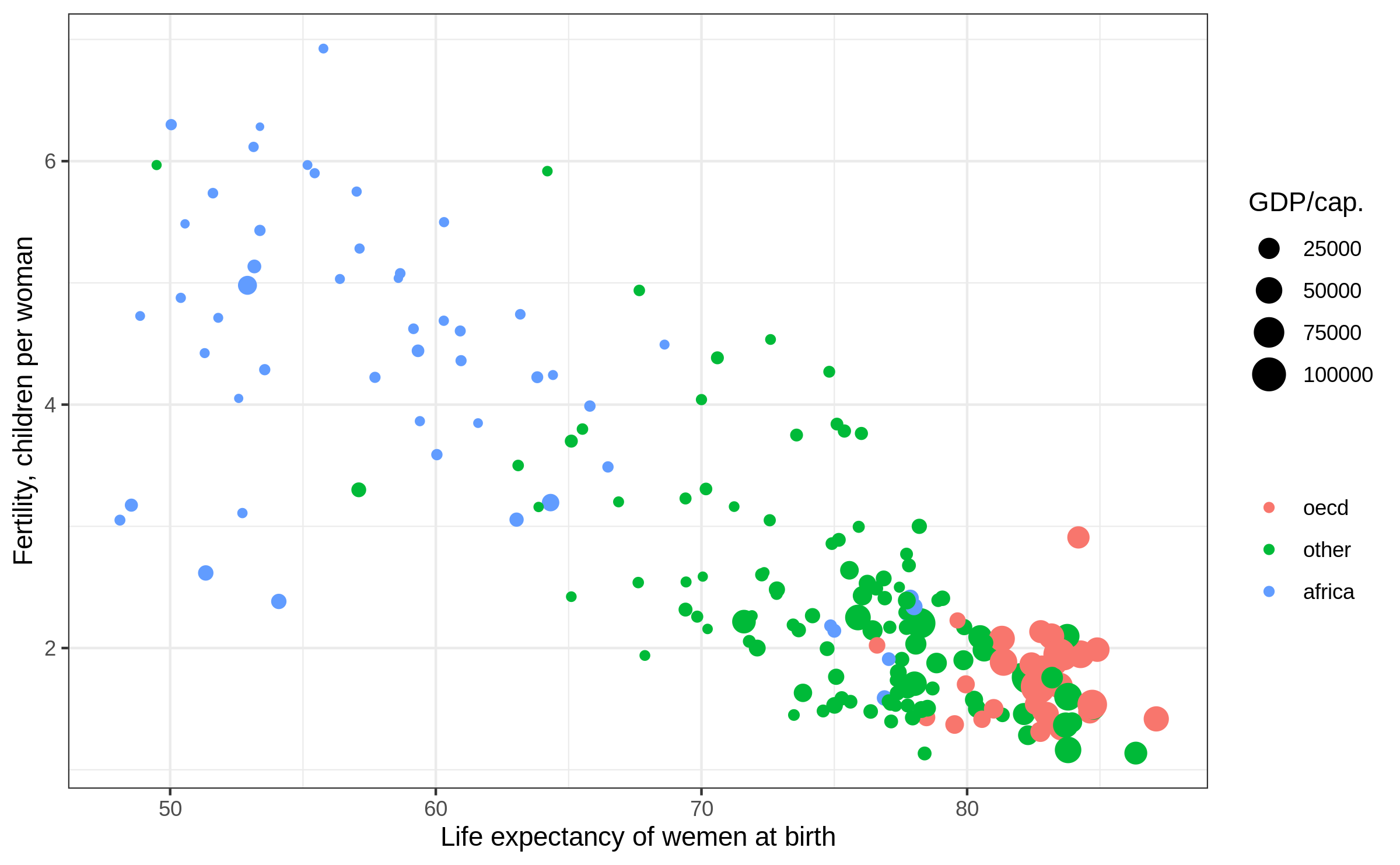
Scatter plot: make it rich with size
References
Weisberg, Sanford. 2005. Applied Linear Regression. John Wiley & Sons, Inc. https://doi.org/10.1002/0471704091.