Simple regression
MP223 - Applied Econometrics Methods for the Social Sciences
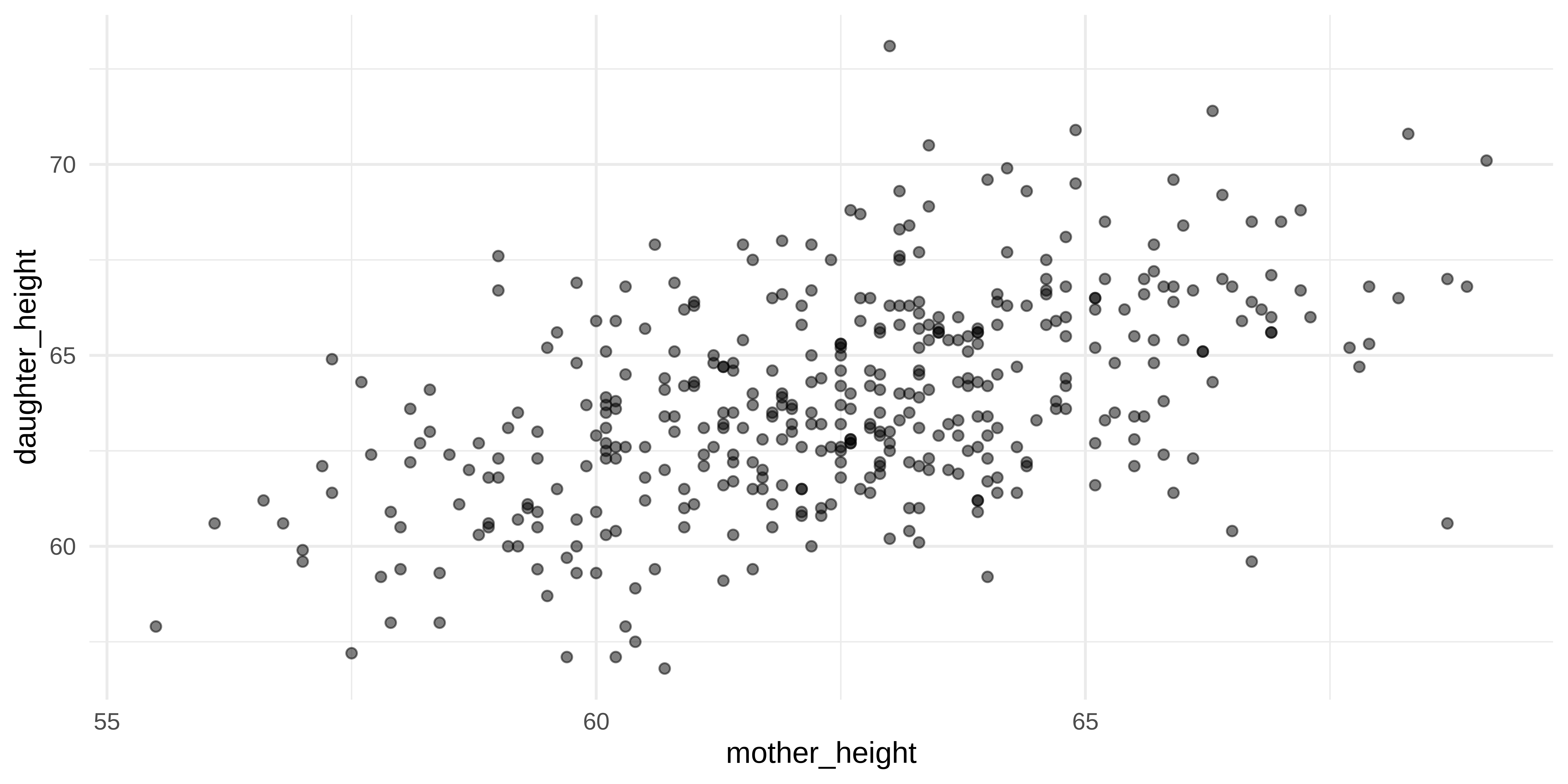
Exploring data (Scatter plot)
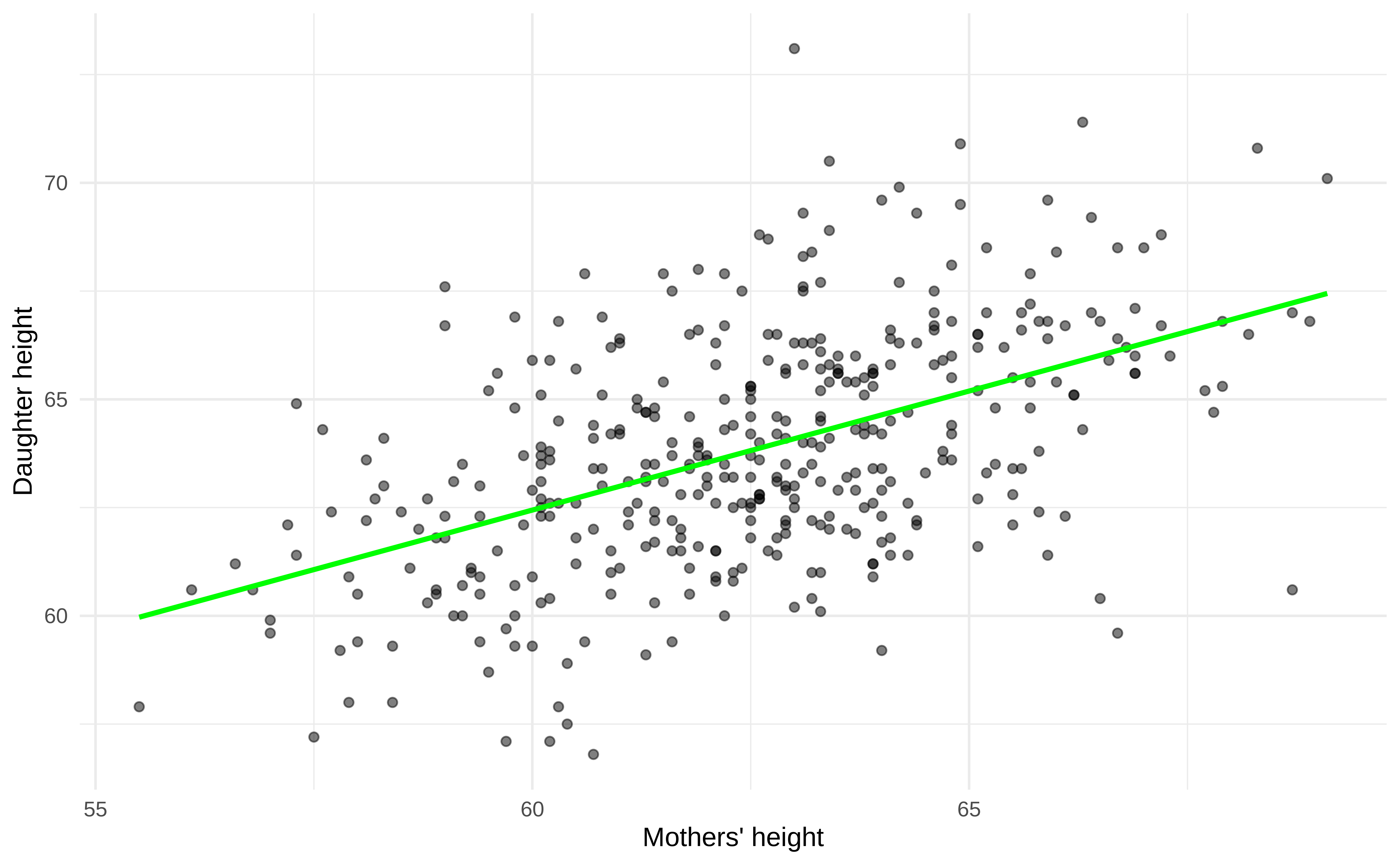
Simple regression line
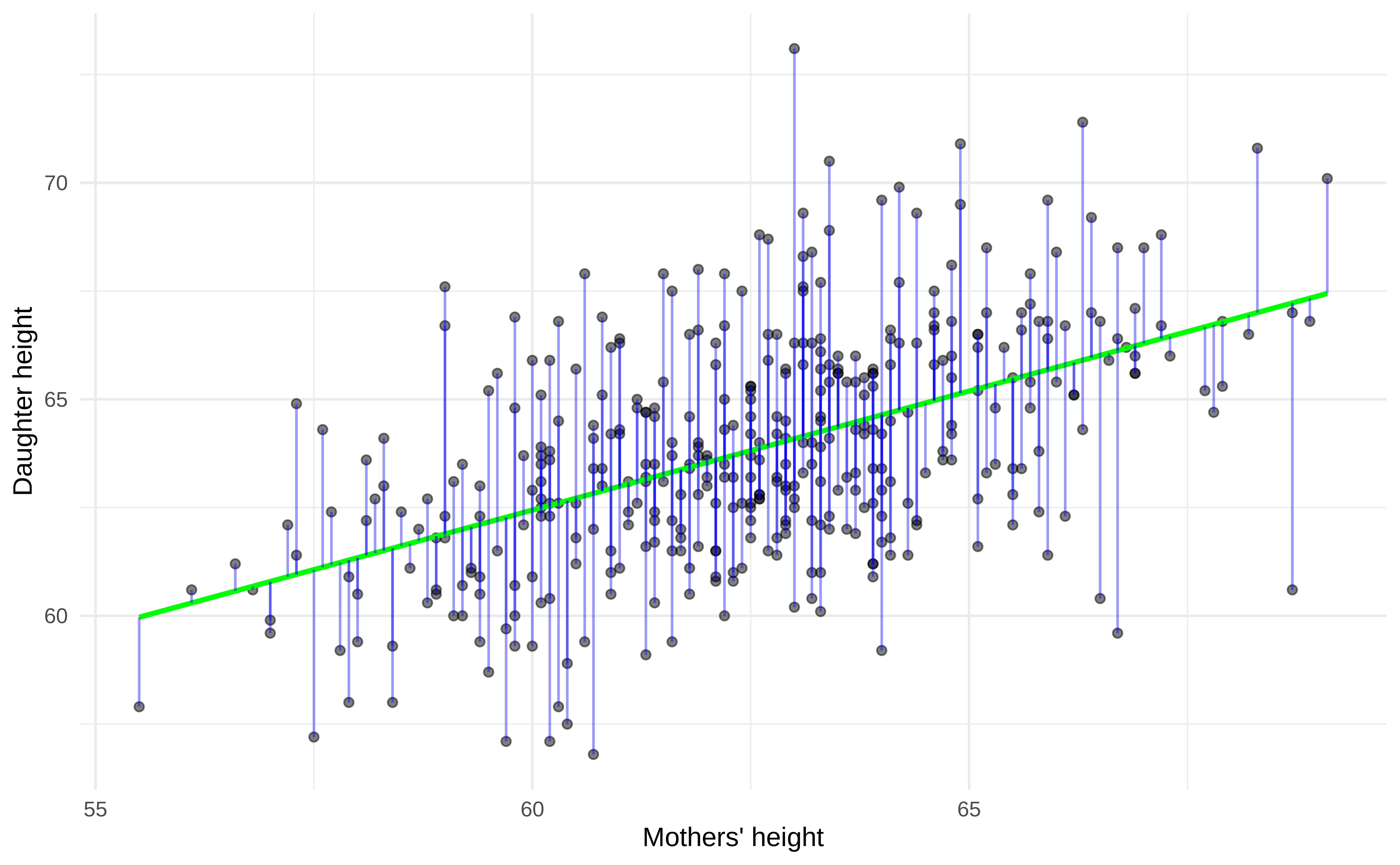
Residuals
Ordinary Least Square (OLS)
“finds” values for \(\hat{\beta}_0\) and \(\hat{\beta}_1\)
each new value of \(\hat{\beta}_0\) and \(\hat{\beta}_1\) generates new regression line;
Code
plt +
geom_segment(
aes(x = mother_height, xend = mother_height,
y = daughter_height, yend = predict(fit)),
color = "blue",
alpha = 0.4
) +
geom_abline(intercept = 33, slope = 0.49, color = "black") +
geom_abline(intercept = 5, slope = 0.95, color = "black") +
geom_abline(intercept = 25, slope = 0.62, color = "black")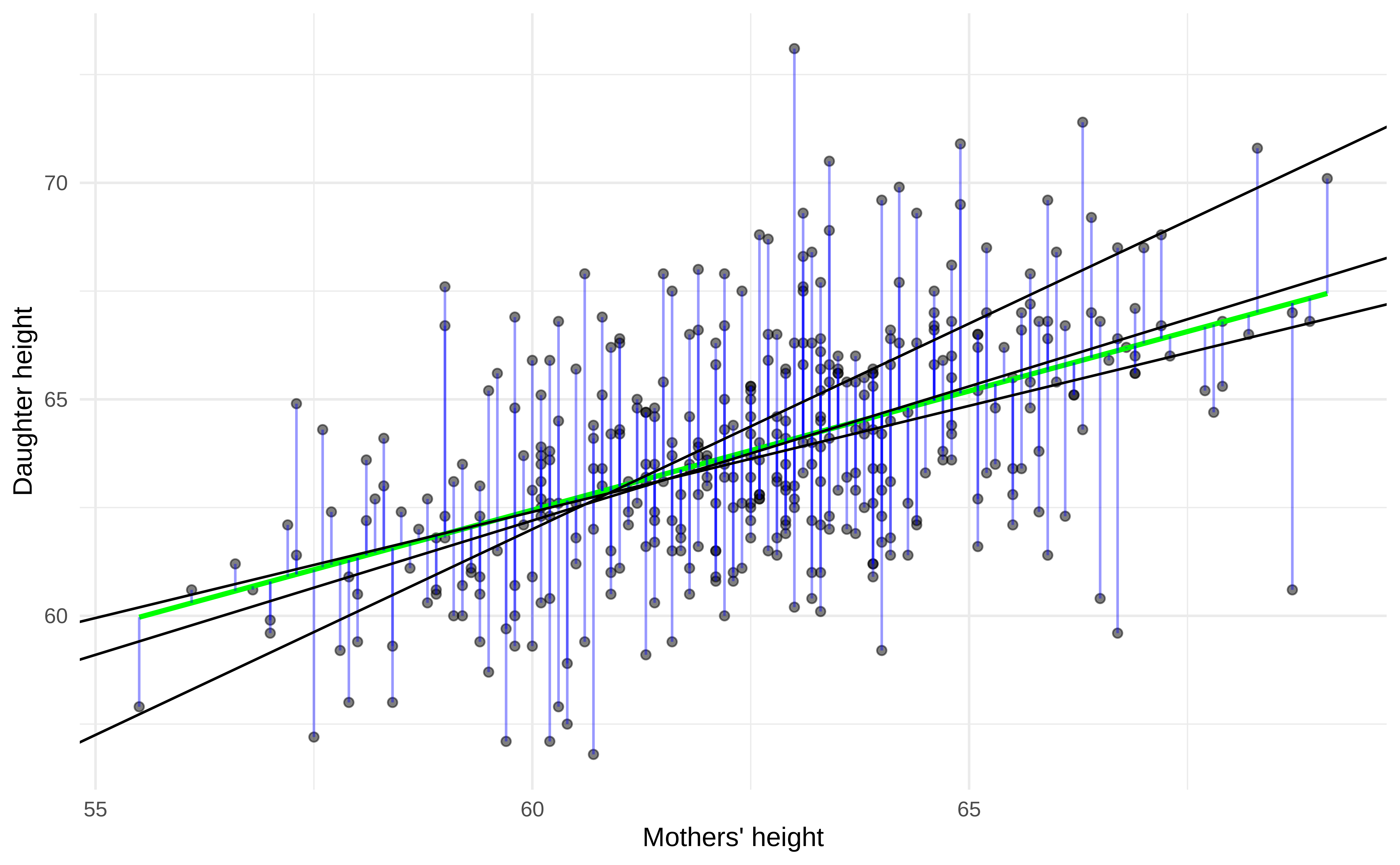
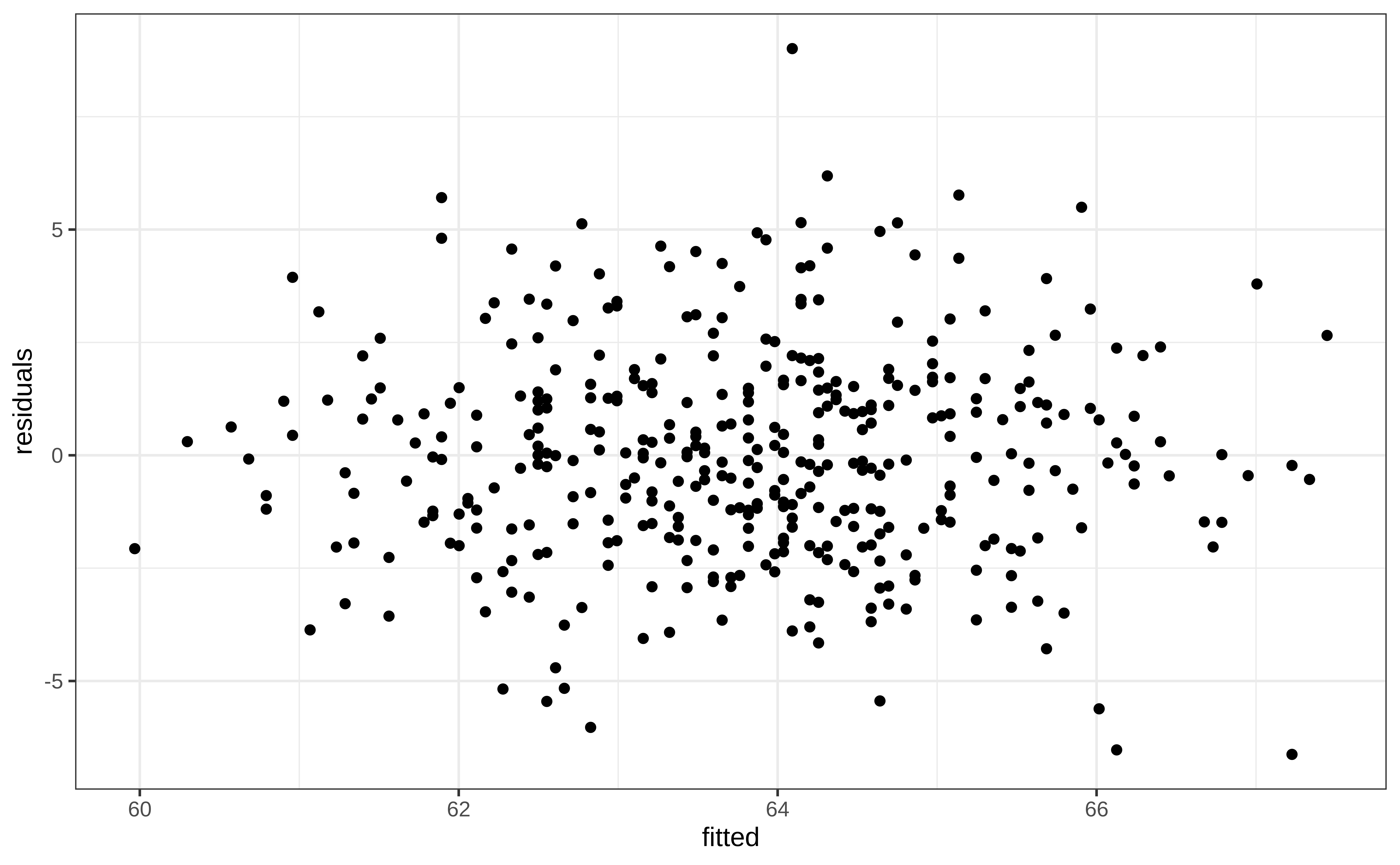
Residuals vs fitted (2/3)
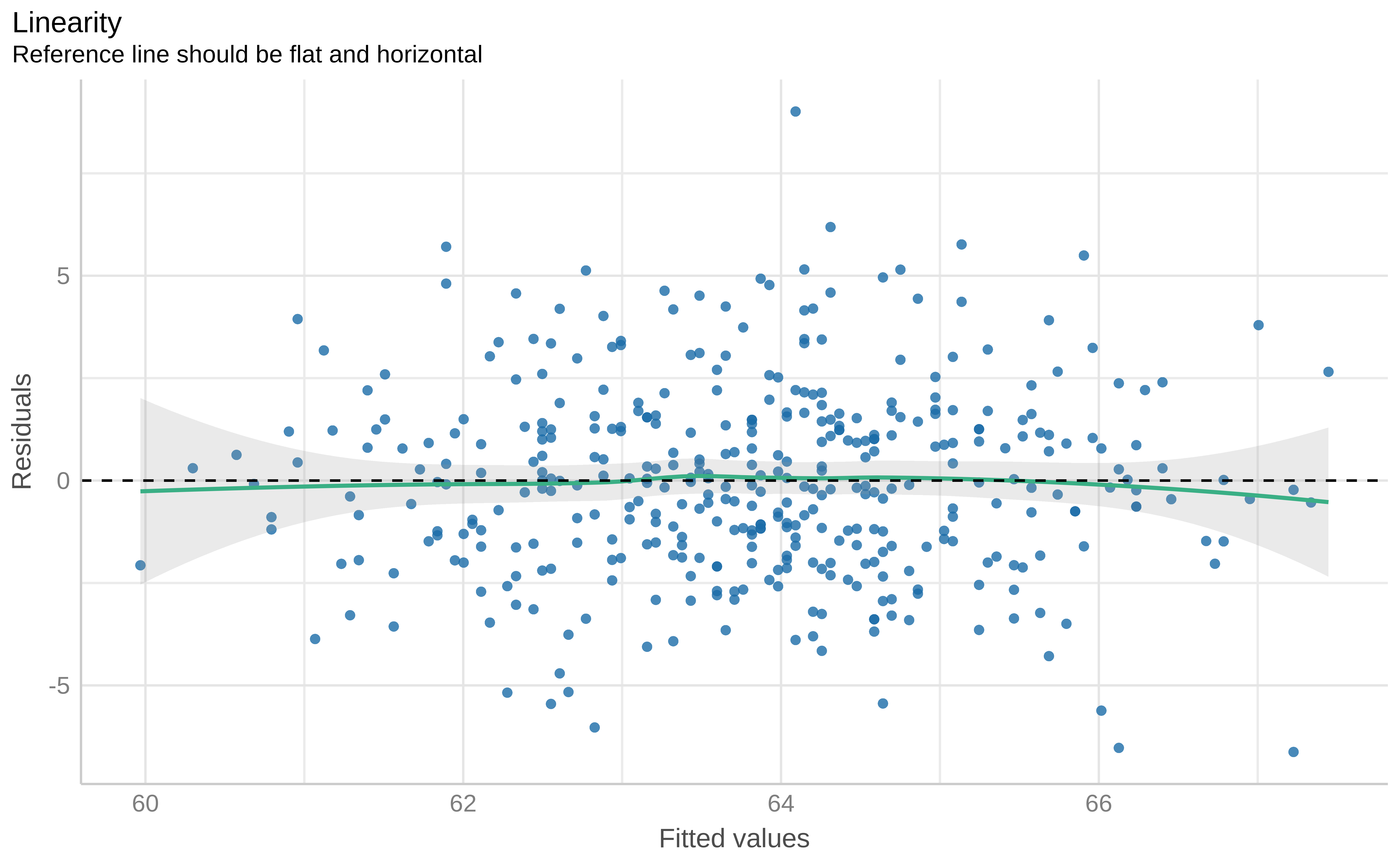
Residuals vs fitted (3/3)
References
Pearson, Karl, and Alice Lee. 1903. “On the Laws of Inheritance in Man: I. Inheritance of Physical Characters.” Biometrika 2 (4): 357. https://doi.org/10.2307/2331507.
Weisberg, Sanford. 2005. Applied Linear Regression. John Wiley & Sons, Inc. https://doi.org/10.1002/0471704091.